


February 13, 2023
To Improve Data Availability, Think ‘Right-Time’ Not ‘Real-Time’

(Image courtesy Dillon Bostwick)
To improve data quality, cost, and access to information, streaming should be a central component of all data infrastructure, regardless of “real-time” adoption.
When defining their data strategy, organizations often follow a standard process. First, the data teams will first gather a list of data applications from their business. Then, they define requirements such as the desired data speed for each data application. Per decades-old data warehousing conventions, data that doesn’t need to be real-time gets batch-loaded nightly or hourly at best. Data architects then reserve streaming technology for niche real-time applications that require sub-minute latencies (see fig. 1).
While a familiar decision process, this thinking encourages a false separation between batch and streaming that limits data-driven teams from maximizing the quality and availability of information across their business.
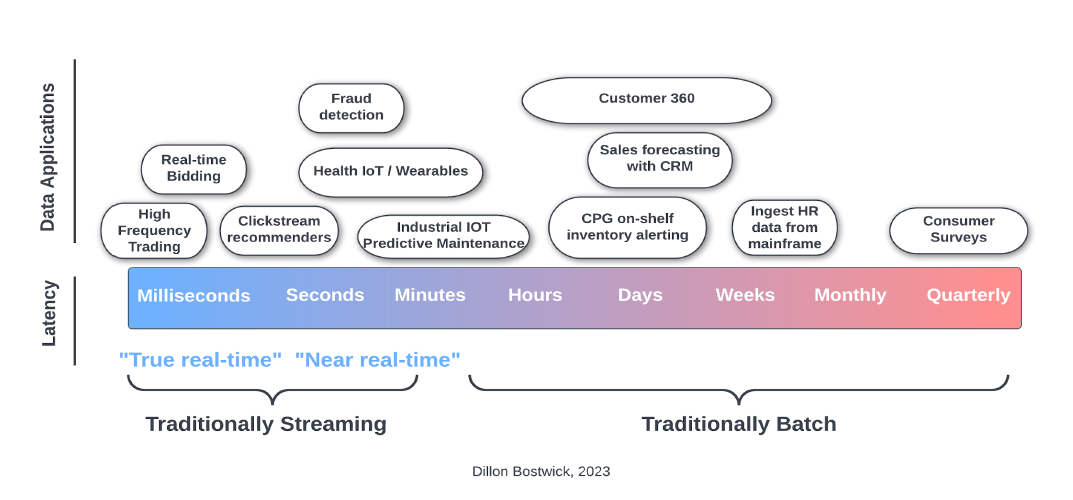
Fig. 1. Typical streaming vs. batch use case planning (Image courtesy Dillon Bostwick)
For example, imagine an analytics engineer at a retail company who creates a weekly inventory report. The CEO loves the weekly report and asks to see the data daily. The analytics engineer then spends several days modifying data pipelines to refresh daily. Due to the global pandemic, the retail business urgently decides to prioritize a BOPIS (Buy Online, Pickup In-Store) program and needs to see inventory down to the minute. Now, the engineer must reconfigure the entire ERP (Enterprise Resource Planning) ingestion and migrate the data lake to get the data incrementally, which could take months or even years to re-productionize. During this large migration, the company loses millions to retailers that could immediately shift to minute-level inventory data awareness.
Data architectures that separate stream and batch processing also require more maintenance and computing cost (see fig. 2). We saw this with lambda architectures, which tried to embrace the stream vs. batch problem but ultimately created source-of-truth issues and increased
maintenance costs (read Apache Kafka co-creator Jay Kreps’ detailed thoughts on this here).
The lambda architecture was invented in 2011 by the creator of Apache Storm, claiming to have finally beaten the CAP theorem. In 2012, Gartner considered Complex Event-Processing to be at its peak of inflated expectations, with a five to 10 year runway to productivity (see fig. 3).
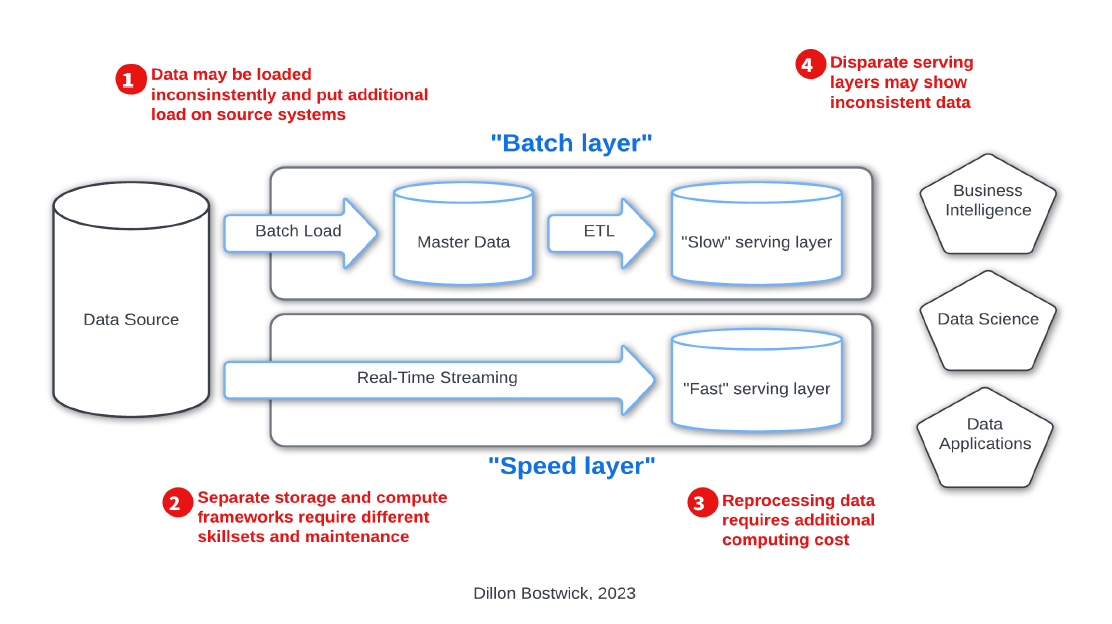
Fig. 2. Problems with Lambda Architecture (Image courtesy Dillon Bostwick)
Over the last five years, I worked with many companies trying to embrace streaming but struggled with its complexity, reserving it for highly specialized projects. In 2023, we’re now largely past streaming’s hype hangover, and the technology has evolved tremendously since the turn of the 2010s. One of the most significant changes I’ve witnessed is an increase in simplicity and unification of streaming with existing batch-based APIs and storage formats. We’re seeing newer products like Databricks’ Delta Live Tables and ACID-based storage formats that unify batch and streaming, such as Delta Lake. In addition, Spark introduced a single API for both
batch and streaming. Other tools like ksqlDB and Apache Flink support a simple SQL API for streaming as well.
I believe these technology changes open up a potentially disruptive rethinking of the benefits of streaming’s underlying reliability guarantees by changing how we design our data architectures and, therefore, our overall data strategy.
To improve agility, cost, and data freshness, data strategies of this decade should start with unified data architectures that unite batch with streaming (see fig. 4).
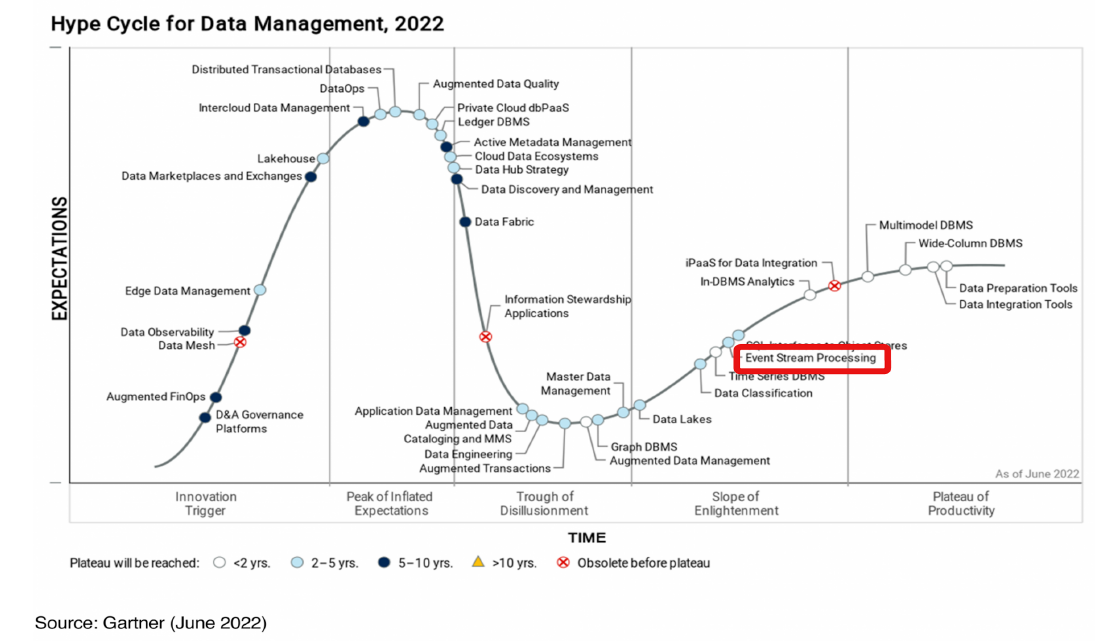
Fig. 3. Hype Cycle for Data Management, 2022 (Image courtesy Gartner)
Then, data engineers should take inventory of all the available data sources, their characteristics, and how frequently they become available. Working backward from the end application and ultimate value, users then define scheduling rules based on the business’s end-to-end latency needs (see fig. 5).
When done successfully, this framework gives the business stakeholders the power to “dial the knob” of data freshness, cost, and quality. As we saw in the BOPIS example, dialing the knob is a massive competitive advantage for both the business and the data engineers because the data freshness can adjust to the needs of the business without relying on infrastructure changes. Our retailer CEO could dial the scheduler to see minute-level inventory updates without even opening a ticket to IT.
Therefore, we must get out of the mindset of reserving streaming for complex “real-time” use cases. Instead, we should use it for “Right-time processing.”
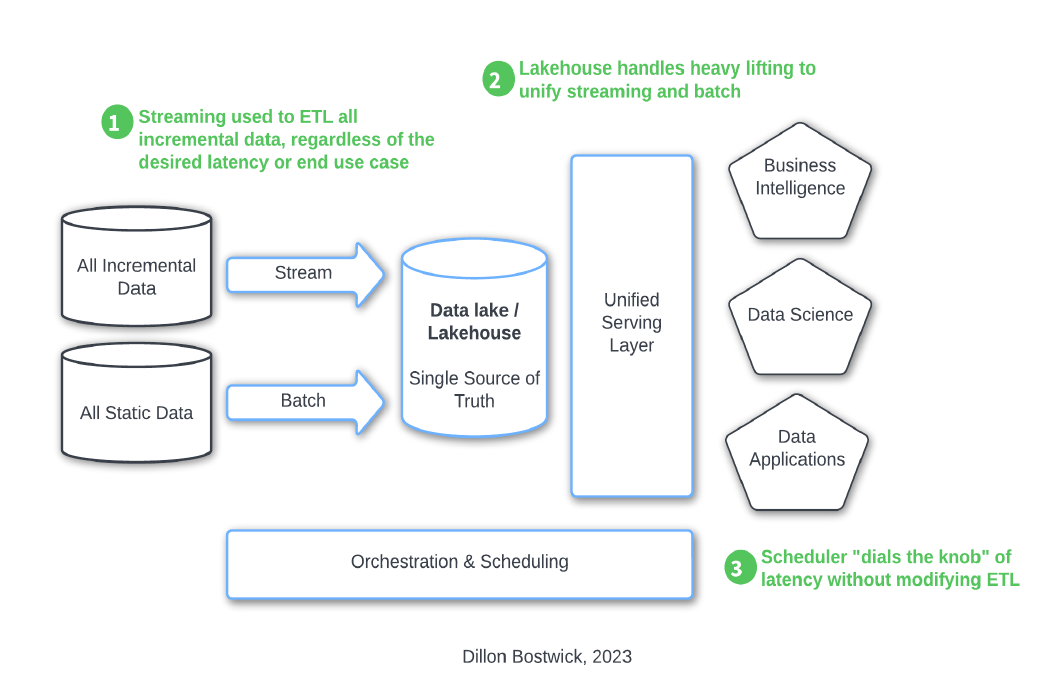
Fig. 4. A unified batch and streaming data architecture (Image courtesy Dillon Bostwick)
Deeper Look
Here are more ways organizations can benefit from streaming even if they don’t need real-time latencies.
1. Reduce Stale Decision-Making
Most BI reports and decision-making aids do not indicate their data freshness. While shocking, we usually take this for granted as a relic of traditional ETL and data warehousing. As a result, analysts or data scientists rarely know how up-to-date the curated datasets are, even when used to support critical decisions and predictions.
Gartner estimates poor data quality costs organizations an average of $12.9M annually and predicts most data-driven organizations will focus heavily on data quality in the coming years. Data freshness is a particularly critical yet overlooked form of poor data quality. We should treat data freshness as a key data quality metric in addition to the data cleanliness itself. With a right-time system, anyone can dial the knob to get the latest report and have full awareness of the report’s freshness before finalizing a critical decision.
For a deeper look into data quality and freshness considerations, watch my colleague’s and my presentation, “So Fresh and So Clean.”
2. Reduce the risk of faulty AI systems
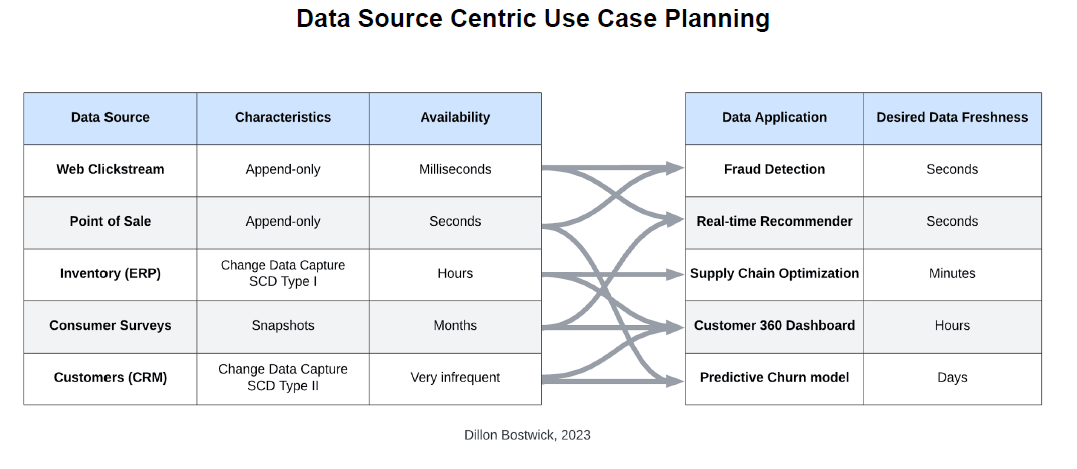
Fig. 5. Data Source Centric Use Case Planning (Image courtesy Dillon Bostwick)
In addition to decision-making, predictive analytics programs using machine learning carry massive liability due to stale data. For example, Zillow’s AI models recently cost them $500M inlosses because models were trained on static data about the housing market. The models made bad bets on homes once real-world conditions changed. This is really another data freshness problem known as concept drift. We are beginning to explore solutions to concept
drift, which mostly boil down to getting your data freshness synchronized right. To do this, architectures that solve for concept drift require a streaming component9, even if you’re not doing real-time AI.
3. Improve Agility
Digital native companies have proven that true real-time predictive modeling leads to exponential value. Just look at ByteDance, which achieved a whopping $200B valuation at a record pace thanks to its impressive user engagement. To achieve this, they are at the global forefront of real-time machine learning, implementing clickstream-based recommenders that operate in milliseconds and keep audiences hooked for hours.
While at the frontier of real-time AI, these tech leaders are inspiring existing businesses to create roadmaps to their own “real-time” visions. When this shift accelerates, many organizations will inevitably struggle to transform as they will have to rip out their current batch data infrastructure entirely, while others will achieve success akin to these digital natives.
Implementing a right-time system today future-proofs a transformation to real-time without data migrations, large code rewrites, and operational overhead. When ready to fund your own millisecond-level projects, you can easily redial the knob.
4. Improve Cloud Costs and Predictability
Combining replication techniques like Change Data Capture with event-streaming frameworks, you can incrementally process data using a fraction of the computing power required by large batch processes. In fact, streaming reduces the amount of data reprocessing via its reliability guarantees, even if you don’t need the data quickly.
This runs contrary to a common misconception that “streaming is expensive” because servers are always on, negating the advantage of cloud elasticity. With streaming, the cost should scale linearly with data volume. Newer products are also offering autoscaling features for streaming, making this no longer a concern in the cloud.
Streaming can also improve cost predictability when proper infrastructure monitoring is in place, giving real-time visibility into cost spikes and bottlenecks. Contrast this to getting invoiced for runaway cloud costs from batch processes many days after they’ve occurred.
Conclusion: Recent advances in the simplification and unification of streaming with batch systems allow us to benefit from the reliability of streaming tools in many use cases, even if the use cases don’t require seconds or milliseconds of latency. This means that streaming can have diverse benefits to data architecture which ultimately translates into less decision-making risk, improved agility, and improved cost efficiencies.
About the author: Dillon Bostwick is a Solutions Architect at Databricks, where he’s spent the last five years advising customers ranging from startups to Fortune 500 enterprises. He currently helps lead a team of field ambassadors for streaming products and is interested in improving industry awareness of effective streaming patterns for data integration and production machine learning. He previously worked as a product engineer in infrastructure automation.
Related Items:
Why the Open Sourcing of Databricks Delta Lake Table Format Is a Big Deal
Is Real-Time Streaming Finally Taking Off?
Leading Solution Providers

















