


April 27, 2023
Semantic Layer Belongs in Middleware, and dbt Wants to Deliver It

(AI-generated/Shutterstock)
The folks at dbt Labs think the data transformation tool is the proper place to implement and manage a semantic data layer, as opposed to the BI tool or the data warehouse, where it has traditionally resided. And later this year, it plans to deliver a semantic layer built into its widely used data transformation software.
A semantic layer is an abstraction used in data analytics designed to help organizations define the exact metrics, measures, and values that are important to them. The process helps the organization standardize what figures it’s going to use instead of allowing every data stakeholder to calculate the figures themselves, which leads to data chaos.
“You can think of it as revenue metrics, or active user metrics, or how many customers do you have,” says Anna Filippova, senior director of community and data at dbt Labs. “It creates a layer of abstraction and it allows you to say definitively that this is the customer number, as opposed to this is a customer value somewhere in your dashboard. It’s the ability to say, Okay, the business has decided that this is the correct number of customers over time, and so I can trust it.”
This semantic layer has traditionally been something that results from the data modeling process often undertaken when an analytics team implements a business intelligence tool for the first time. Data engineers may also define their semantic layer when implementing a data warehouse or a data mart.

dbt users define metrics using YAML (image source: dbt Labs)
However, defining the semantic layer in the BI tool or the data warehouse can lead to downstream problems, Filippova says. For example, analysts using a different tool to access data may come up with a different measure, she says. Keeping the semantic layer in synch between the BI tool and the data warehouse–or between two or more BI tools or databases–is another problem.
“Maybe you’re working in your BI tool and you’re like, ‘I want to know the number of customers.’ Or you’re working on Google Sheets and you want to know the number of customers or you’re working in Jupyter notebook because you’re a machine learning engineer and you want to use the number of customers as an input into some forecast that you’re doing,” she says.
If the organizations puts the semantic layer upstream from the BI tool or the warehouse–say in the ETL middleware that’s used to load data into the warehouse, or just in the transformation tool itself–instead of putting it in the BI tool or data warehouse, “then everyone can refer to that same number,” Filippova says. That leads to better, more accurate data, which leads to better analytics and machine learning, etc.
In a perfect world, the semantic layer would have lived in the ETL or transformation tool from the beginning. Having the semantic layer there would have avoided many data problems over the years. Obviously, we don’t live in a perfect world, and so instead we have a mishmash of semantic layers residing in various databases and BI applications.
It’s a bit of a bold move for dbt Labs to grab the torch for semantic modeling. Filippova says the lack of standardization is leading reason why the semantic layer has never resided higher upstream in the ETL/ELT or tranformation layer, and instead has been pushed downstream into the database and BI tools, where confusion propagating from semantic conflicts is common.
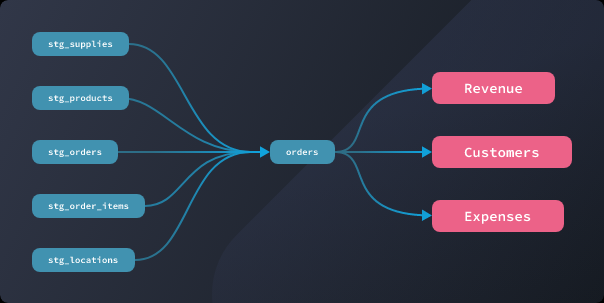
Metrics created by users are then populated in dbt’s DAG (image source dbt Labs)
“Obviously I’m biased here, working for dbt Labs,” she says. “But it’s because we didn’t really have a transformation standard. And so there wasn’t a catalyst that would enable building an ecosystem around something like this. So the dbt semantic layer only works because there’s an ecosystem around the folks who integrate with it, who are working together on this common vision.”
dbt Labs announced its intention to build a semantic layer last year. Since then, the company has consulted with the dbt community to understand what a semantic layer in the open source tool would look like and how it would function, Filippova says. A preview of the semantic layer was released in October.
“We are tracking towards GA later this year,” she tells Datanami. “One of the things we’ve done since then is we’ve acquired a wonderful company called Transform. And they have an exceptional implementation of aspects of a semantic layer that we’d like to integrate into the product. And so that’s the work that’s happening right now.”
When the semantic layer work is completed, it has the potential to have a major impact on the workflow of analysts and data engineers. For starters, it will eliminate duplicate effort because the definitions of what constitutes a company’s revenues, customers, etc. will occur once in dbt instead of occurring in various BI tools and databases. It will also enable analyst teams to work more quickly, Filippova says.
“It cuts down on a lot of duplicative work across teams and so it really magnifies efficiency, which is also really important right now,” she says. “Everyone is moving much more quickly in order to react to changing market conditions and environmental forces…You don’t really have time at a moment like this to get stuck on how many customers do we have? Is this the right number of customers? Or is it this other thing?”
Organizations always needed to do a bit of modeling when they started with dbt, Filippova says. With the addition of the semantic model abstraction, the directed acyclic graph (DAG) living in dbt will reflect the connection between data tables and the metrics that have been defined by dbt users.
“It’s an example of a few different ways that we’ve expanded that DAG in dbt, that layer on top of SQL,” she says. “We think of it as like nodes in a graph. And so now you can have nodes that are SQL models. You can have nodes that are metrics, and you can have nodes that are Python nodes.”
By building a semantic layer into its product, the folks at dbt Labs hope that it makes it easier for more people to work with more data using more tools, and ultimately result in better, more trustworthy data.
“How do you go beyond the analyst? How do you turn everyone into someone who can work with data, but do it in a way that allows you to keep going digging further and further?” she says. “dbt Labs doesn’t believe that there’s one way to do data visualization. There isn’t one way to work with data at the at the reporting layer. There are different kinds of folks with different experience and tools to be able to do that. So it’s much better for folks to choose the right tool that they want for the job.”
Related Items:
What Is An Analytics Engineer and When Do You Need One?
dbt Rides Wave of Modern, Cloud-Based ETL to New Heights
Meet 2022 Datanami Person to Watch Tristan Handy
Leading Solution Providers

















