


September 18, 2023
Tabular Plows Ahead with Iceberg Data Service, $26M Round

(Maksim-Kabakou/Shutterstock)
Apache Iceberg appears to have the inside track to become the defacto standard for big data table formats at this point. And with today’s $26 million round, the company behind the open source project, Tabular, is better positioned to continue developing an automated Iceberg data management service that can make a messy data lake function like a refined–and open–data warehouse.
The advent of open table formats is one of the biggest things to happen to data lakes in quite a while. Instead of putting the onus on developers or engineers to manage Parquet files in active data lakes to ensure data integrity, table formats like Iceberg and the other two competing formats, Hudi from Uber and Delta from Databricks, provide the ACID guarantees that give customers confidence in the accuracy of the data.
While an Iceberg environment by itself delivers those benefits, it brings its own set of requirements that would normally fall to the data engineer. Ryan Blue, who co-created Iceberg with Dan Weeks while at Netflix, co-founded Tabular in 2021 with Weeks and another former Netflix colleague, Jason Reid, to automate those tasks in an Iceberg environment.
“Tabular is a much broader platform” than just Iceberg, Blue tells Datanami. “We provide a catalog, role-based access controls, and background services to keep data performant and clean. We can do things like age-off data or mask it after a certain period of time. We’ll go null out a column that can no longer be stored, and do sort of these basic heavy lifting tasks that you don’t want to spend on a data engineer’s time.”
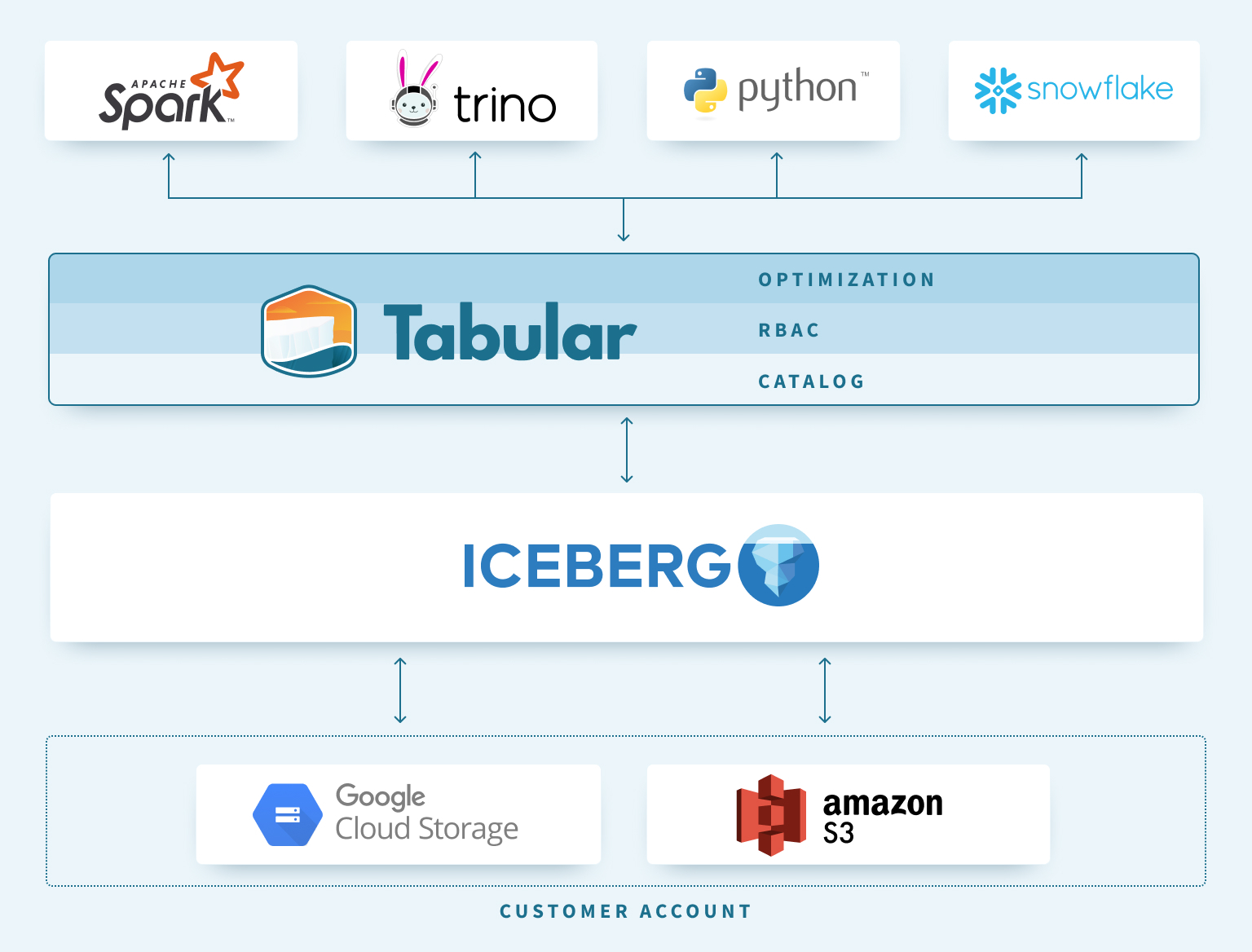
When combined with object storage, Tabular and Iceberg function as the bottom half of a data warehouse (Image source: Tabular)
Tabular’s automated compaction service can shrink the S3 data storage by 50%, and sometimes more. Instead of requiring a human engineer to rewrite a whole bunch of small Parquet files that have been dropped onto S3 (the only object storage Tabular supports right now), the Tabular service will automatically compact all those small files into a fewer number of larger files, thereby reducing storage.
One of Tabular’s early customers slashed its AWS storage bill by upwards of $1 million per year thanks to its use of Tabular. The large gaming company was ingesting 20.2 TB of source Parquet files each day across 4 million files. After Tabular’s data ingestion and compaction routines were implmented, the number of files was reduced to 60,000 across 1,100 Iceberg tables, totalling just 10.4 TB in storage. “You’re never going to get a team of data engineers to go, by hand, tune 1,100 tables, let alone make it 50% smaller,” Blue says. “So it’s a huge win.”
The way Blue sees it, the Tabular service gives data lake customers in the cloud an open storage layer that is a lot smarter than what came before it.
“I think that is one of the pitfalls of coming from the Hadoop landscape, because before, your storage was dumb,” the 2022 Datanami Person to Watch says. “It didn’t do anything for you. You had a catalog that was either [AWS] Glue or the Hive metastore that sort of described what was in S3, and that was it.”
The open table formats give users more confidence that their data is correct and there aren’t dirty reads coming from multiple engines accessing the same piece of data at the same time. The cost to gain those ACID guarantees with table formats is a bit more technical complexity, Blue says. Iceberg maintains more history to ensure data integrity, and sometimes there’s a need to go in and delete that history when it’s no longer needed, which is what Tabular provides.
In other words, an S3 data lake paired with Tabular’s data service functions a lot more like a typical data warehouse does than your typical Hadoop or S3 lake, Blue says.
“I think the analogy of us as the bottom half of a data warehouse makes a lot more sense,” he says. “In the Hadoop space, you don’t think ‘Oh, hey, someone needs to go maintain my tables.’ But in the data warehouse space, you do think that. ‘Of course Snowflake keeps your data compacted and in a performant layout.’![]()
“Well, what service is doing that work?” he continues. “In Hadoop, it was data engineers. It was people that we said, ‘Hey, here’s a scheduler. Go figure out how to make everything efficient.’ We’re just the automated form of that…. We’ll manage compaction and optimization. So we’ll look at the data and each table individually and find out how should we be storing that data for the best query performance, the best storage efficiency, etc.”
Tabular service is currently only generally available on AWS and S3, which it unveiled in March. Tabular customers can use whatever open source query engines they want against their Tabular tables, including EMR and Athena, which was also announced today and is currently in preview. Customers can also use Galaxy, the hosted version of Trino from Starburst, as well as open source Trino or Presto. They can also access data from Snowflake if they like, Blue says.
Today’s $26 million funding round gives the San Jose, California company the financial resources it needs to continue developing the product. Currently, the company has an early preview of Google Cloud Storage, with plans to make that GA soon. The plan calls for supporting Microsoft Azure, Minio, and Cloudflare as well, Blue says.
More than 1,500 people so far have signed up to try out the Tabular service, although not all are paying customers. “We have a fantastic amount of interest in the product that we’ve launched,” Blue says. “We’ve gotten exactly the kind of bottom-up interaction that we were hoping for, with people letting us know what they’d love to see improve.”

Ryan Blue is the CEO and co-founder of Tabular
The eventual goal is to provide data optimization services for just about any object storage system, effectively turning those data lakes into highly performant data warehouses, but without subjecting customers to the lock-in normally associated with those high performance warehouses.
Martin Casado, general partner at Andreesen Horowitz, which particpated in the current round at Tabular that was led by Altimeter Capital, says services like Tabular can help foster an open data ecosystem.
“The cloud ecosystem has begun to consolidate around a small constellation of full-stack vendors, creating a real risk of rent-seeking behavior that can negatively impact customers and stifle innovation,” Casado said in a press release. “Independent and open platforms such as Tabular offer a path to healthy competition and flexibility for enterprises.”
Related Items:
Cloudera Sees Iceberg Everywhere
Iceberg Data Services Emerge from Tabular, Dremio
Apache Iceberg: The Hub of an Emerging Data Service Ecosystem?
Leading Solution Providers

















