


October 24, 2023
Object Storage a ‘Total Cop Out,’ Hammerspace CEO Says. ‘You All Got Duped’

(NAS CREATIVES/Shutterstock)
The mass adoption of object storage systems like Amazon S3 may appear to be a top achievement of the big data era, since we got essentially unlimited storage accessible through REST commands. But to Hammerspace CEO David Flynn, object storage is a “total cop out” that perpetuates data orchestration headaches. “That was the bargain you made with the devil,” Flynn said at the recent HPC + AI on Wall Street event.
The industry standardized on object storage because the market found it too difficult to do the right thing: turning standard NFS into a distributed file system capable of handling cloud scale, Flynn said September 27 during his keynote address at Tabor Communications’ 2023 HPC + AI on Wall Street conference in New York City.
“This is all about fixing the evil that file systems weren’t able to do cloud-scale,” Flynn said. “Let’s face it: the entire reason Amazon created S3–Super Simple Storage–was because file systems are so damn hard to make and even harder to make them scale that they dumbed it down and said ‘Let’s just use REST interfaces from user space and not try to get that high bar of having the OS know how to actually mount it and consume data from it.’
“Object storage was always a cop out, and you guys all got duped into thinking you have to rewrite all of your applications to use it just to get to cloud,” he continued. “And it’s because they didn’t do the hard work of making a real file system that OSes natively know how to use, and that’s still considered the conventional wisdom. ‘Cloud means rewrite everything to use object storage and talk to persistence from user space.’

Hammerspace CEO David Flynn at HPC + AI on Wall Street September 27, 2023
“That is a total cop out,” Flynn said. “It’s throwing the baby out with the bath water. But they had to do it. There was no other way to host the multiple tenants and the huge amount of scale that was needed in the cloud. But that was the bargain you made with the devil to get to the cloud as you rewrite that stuff.”
These were strong words, but with decades of experience in the enterprise IT and HPC markets, Flynn has learned a thing or two about high performance storage. Before co-founding flash storage startup Fusion-io, which was acquired by SanDisk for $1.1 billion 2014, Flynn helped build some of the world’s biggest supercomputers at Linux Networx. These travels showed Flynn a significant gap exists between the enterprise storage market and the HPC community, which he proposes to help fill with his data orchestration startup, Hammerspace.
AI’s Perfect Storm
The advent of AI has created a “perfect storm” of needs that will demonstrate that the object storage compromise is no longer sufficient, Flynn said.
Everybody now needs HPC capabilities to train AI models, but distributed file systems are the only way to efficiently manage I/O and keep GPU nodes saturated. The current status quo with object storage, which requires users to rewrite their applications from native NFS to use HTTP commands (i.e. REST) over the network, doesn’t cut it.

Data I/O remains a bottleneck to AI
While NFS is the defacto standard in the enterprise NAS business and is natively supported in Linux, NFS has had its share of false starts. The group behind NFS tried to address the statefulness issue with NFS 4.0, but ended up butchering the file system, Flynn said.
“NFS 4 took all of the sins of NFS 3–the statelessness and all of that–and tried to remedy it by adding statefulness so that you can cache stuff and get it more efficient,” he said. “But it was retrofitted in both the clients and the servers. And you ended up with all of the overheads and evils of statelessness combined with the overheads and evils of statefulness.”
For example, having a program create a file and then write it so another program on the same computer read it, took five round trips serial to the filer in NFS 3. With NFS, that jumped to 15 serial round trips, Flynn said.
“They kind of messed up when they introduced all the statefulness because it wasn’t well tuned to really be exploited by the clients and servers together, and it ended up just being massive overhead,” Flynn said. “We still pay the price today. You want to go to NFS 4 to maybe get better security or other things, and yet you end up paying a massive price in a performance perspective. Basically, NFS has from inception always kind of sucked.”
After he left Fusion-io, Flynn vowed to find a way to remedy this situation. He teamed up with Trond Myklebust, the maintainer and lead developer of the Linux kernel NFS client, and co-founded a new venture Hammerspace. Led by Myklebust, a Hammerspace co-founder and its CTO, the team took what was effectively an academic project to develop a parallel version of NFS led by Los Alamos National Lab and turned it into an enterprise-ready product.
“We introduced the NFS 4.2 spec. That came from my team here at Hammerspace,” Flynn said. “Thanks to Trond, we were able to trick it out to actually really work well, especially with our NFS 4.2 parallel NFS server.”
A Global Storage Abstraction
Developing a parallel version of NFS was important to Hammerspace, but it was but one step on its overall journey to the ultimate goal: creating a new storage abstraction that eliminates the limitation of physical storage and puts data back in the driver’s seat.
As a data orchestration layer, Hammerspace essentially connects any storage infrastructure, whether it speaks NFS, object storage, or even block storage, to an application. Whether it’s a NAS device from NetApp, Dell EMC, Qumulo, or Vast–whether it’s an Amazon S3 bucket or a Linux server configured as a storage node–Hammerspace can take all that data and make it appear to an application to be sitting on local storage, even if the data is sitting on the other side of the world.
Just as characters in Japanese cartoons can pull a mallet out of thin air and whack their opponents in the head, Hammerspace becomes the thin air (or the single global namespace) out of which you can pull any piece of data (just don’t hit your opponents in the head with it).
The key to this seeming magic trick is unified metadata, Flynn said.
“Hammerspace solves the seeming paradox of how can you have data everywhere and anywhere you need it, without ever having copied it?” Flynn said. “That’s not because it’s not local and accessed at local access performance. It’s because the metadata is unified. So while the data is physically distributed, the metadata is logically unified.”
Pulling the metadata out of the storage layer into a new layer that transcends those other layers addresses a litany of data management pain points, Flynn said. Data migration becomes a thing of the past when you can hook up Hammerspace to an existing network file system and instantly start accessing it through an application previously connected to a different storage repository, Flynn said.
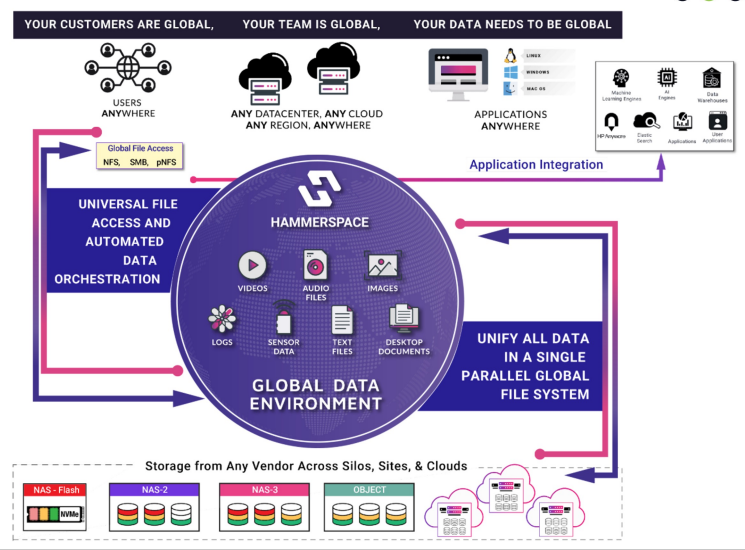
Hammerspace implements a global data abstraction layer atop physical storage
“When was the last time you had to think about having your data when you move from one phone to the next, or when you go from your phone to your laptop or tablet?” he said. “Our consumer data already lives in a Hammerspace and the iOS platform, the Android platform have basically orchestrated your experience and your data for you. That’s what we’re talking about doing here, but for the petabytes to exabytes scale unstructured data that is behind everything.”
The headache of maintaining a high availability server configuration will be a thing of the past when Hammerspace is ensuring that data from one node can be accessed from another node. “You can get rid of all of these different forms of copy, like your data copy sync programs, the data migration tasks, when you’re going from one system to another,” Flynn said.
In the end, Flynn hopes that Hammerspace’s notion of data orchestration flips the script on modern ideas of data management. Instead letting data storage define what data is and what it means to us, the data orchestration layer defines the data once, and makes where it’s stored a mere implementation detail.
“Data orchestration differs from data management in a very simple way: Data management is what you do from the outside of the data presentation layer,” Flynn said. “The real evil is the fact that the file system is embedded in the storage system or service. The data presentation layer being inside of that storage system means that the data is really nothing but a mirage that is being rendered by that storage. And if you put it in different storage, it’s by definition different data, because its very existence is an artifact of the storage system or service presenting it.”
It seems very natural to say that your data exists in your NAS filer or your S3 bucket, because that’s what possesses the metadata and presents the data to you, Flynn said. But that’s actually getting it backward, because data, by definition, is a higher level abstraction than storage, which is just infrastructure. And therein lies the key thing that Hammerspace enables.
“Data doesn’t exist except for as rendered by storage,” Flynn said. “That seems very natural to say, but it is upside down. It means that the infrastructure is in charge and the platform layer is dependent upon it. But with Hammerspace, that changes because you pull all of the metadata out of the storage layer into something that can transcend any of those storage systems. So now you have where data can sit appropriately as the higher level thing that you focus on, and where the data actually lives, on which storage, can change.”
You can view Flynn’s entire HPC and AI on Wall Street presentation by registering at www.hpcaiwallstreet.com.
Related Items:
Hammerspace Raises $56M to Reimagine Data Orchestration
Three Ways to Connect the Dots in a Decentralized Big Data World
Hammerspace Hits the Market with Global Parallel File System
Leading Solution Providers

















