

February 26, 2024
Putting Your Data On the Table

(Tee11/Shutterstock)
One of the big breakthroughs in data engineering over the past seven to eight years is the emergence of table formats. Typically layered atop column-oriented Parquet files, table formats like Apache Iceberg, Delta, and Apache Hudi provide important benefits to big data operations, such as the introduction of transactions. However, the table formats also introduce new costs, which customers should be aware of.
Each of the three major table formats was developed by a different group, which makes their origin stories unique. However, they were developed largely in response to the same type of technical limitations with the big data status quo, which impacts business operations of all types.
For instance, Apache Hudi originally was created in 2016 by the data engineering team at Uber, which was a big user (and also a big developer) of big data tech. Hudi, which stands for Hadoop Upserts, Deletes, and Incrementals, came from a desire to improve the file handling of its massive Hadoop data lakes.
Apache Iceberg, meanwhile, emerged in 2017 from Netflix, also a big user of big data tech. Engineers at the company grew frustrated with the limitations in the Apache Hive metastore, which could potentially lead to corruption when the same file was accessed by different query engines, potentially leading to wrong answers.

Image source: Apache Software Foundation
Similarly, the folks at Databricks developed Delta in 2017 when too many data lakes turned into data swamps. As a key component of Databricks’ Delta Lake, the Delta table format enabled users to get data warehousing-like quality and accuracy for data stored in S3 or HDFS data lakes–or a lakehouse, in other words.
As a data engineering automation provider, Nexla works with all three table formats. As its clients’ big data repositories grow, they have found a need for better management of data for analytic use cases.
The big benefit that all table formats bring is the capability to see how records have changed over time, which is a feature that has been common in transactional use cases for decades and is fairly new to analytical use cases, says Avinash Shahdadpuri, the CTO and co-founder of Nexla.
“Parquet as a format did not really have any sort of history,” he tells Datanami in an interview. “If I have a record and I wanted to see how this record has changed over a period of time in two versions of a Parquet file, it was very, very hard to do that.”
The addition of new metadata layers within the table formats enables users to gain ACID transaction visibility on data stored in Parquet files, which have become the predominant format for storing columnar data in S3 and HDFS data lakes (with ORC and Avro being the other big data formats).
“That’s where a little bit of ACID comes into play, is you’re able to roll back more reliably because now you had a history of how this record has changed over a period of time,” Shahdadpuri says. “You’re now able to essentially version your data.”
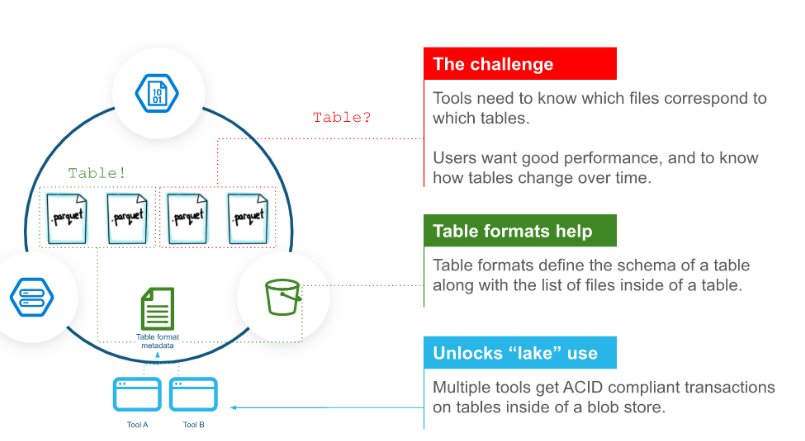
Image source: Snowflake
This capability to rollback data to an earlier version comes in handy in particular situations, such as for a data set that is continually being updated. It’s not ideal in cases where new data is being appended to the end of the file.
“If you’re if your data is not just append, which is probably 95% of use cases in those classic Parquet files, then this tends to be better because you’re able to delete, merge and update much better than what you would have been able to do with the classic Parquet file,” Shahdadpuri says.
Table formats allow users to do more manipulation of data directly on the data lake, similar to a database. That saves the customer from the time and expense of pulling the data out of the lake, manipulating it, and then putting it back in the lake, Shahdadpuri says.
Users could just leave the data in a database, of course, but traditional databases can’t scale into the petabytes. Distributed file systems like HDFS and object stores like S3 can easily scale into the petabyte realm. And with the addition of a table format, the user doesn’t have to compromise on transactionality and accuracy.
That’s not to say there are no downsides. There are always tradeoffs in computer architectures, and table formats do bring their own unique costs. According to Shahdadpuri, the costs come in the form of increased storage and complexity.
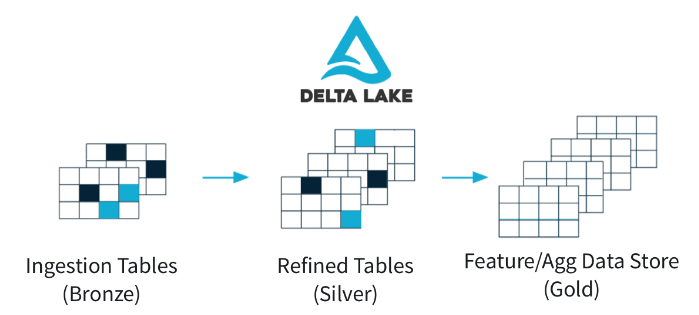
Image source: Databricks
On the storage front, the metadata stored by the table format can add as little as a 10 percent storage overhead, all the way up to a 2x penalty for data that’s continually changing, Shahdadpuri says.
“Your storage costs can increase quite a bit, because earlier you were just storing Parquet. Now you’re storing versions of Parquet,” he says. “Now you’re storing your meta files against what you already had with Parquet. So that also increases your costs, so you end up having to make that trade off.
Customers should ask themselves if they really need the additional features that table formats bring. If they don’t need transactionality and the time-travel functionality that ACID brings, say because their data is predominantly append-only, then they may be better off sticking with plain old Parquet, he says.
“Using this additional layer definitely adds complexity, and it adds complexity in a bunch of different ways,” Shahdadpuri says. “So Delta can be a little more performance heavy than Parquet. All of these formats are a little bit performance heavy. But you pay the cost somewhere, right?”
There is no single best table format, says. Instead, the best format emerges after analyzing the specific needs of each client. “It depends on the customer. It depends on the use case,” Shahdadpuri says. “We want to be independent. As a solution, we would support each of these things.”
With that said, the folks at Nexla have observed certain trends in table format adoption. The big factor is how customers have aligned themselves with regards to the big data behemoths: Databricks vs. Snowflake.
As the creator of Delta, Databricks is firmly in that camp, while Snowflake has come out in support of Iceberg. Hudi doesn’t have the support of a major big data player, although it is backed by the startup Onehouse, which was founded by Vinoth Chandar, the creator of Hudi. Iceberg is backed by Tabular, which was co-founded by Ryan Blue, who helped created Iceberg at Netflix.
Big companies will probably end up with a mix of different table formats, Shahdadpuri says. That leaves room for companies like Nexla to come in and provide tools to automate the integration of these formats, or for consultancies to manually stitch them together.
Related Items:
Big Data File Formats Demystified
Open Table Formats Square Off in Lakehouse Data Smackdown
The Data Lakehouse Is On the Horizon, But It’s Not Smooth Sailing Yet
Applications:
Data Management
Sectors:
Financial Services
Leading Solution Providers









Tabor Network
















