


June 14, 2024
Databricks Goes Serverless, Simplifying its Data Platform

(whiteMocca/Shutterstock)
One of the complaints heard about Databricks over the years–that it’s complex to set up and sometimes difficult to use–will need to be revisited now that the company is making its entire data platform serverless.
Databricks currently offers a serverless option for some functions, meaning that customers aren’t responsible for spinning up clusters or spinning them back down when they’re done. But most of the platform relies on underlying compute clusters that cost the customers money whether or not they’re using them.
That is changing. During his keynote at the company’s Data + AI Summit on Wednesday, Databricks CEO and co-founder Ali Ghodsi announced that, starting July 1, the entire Databricks platform will be available as serverless.
“With serverless, you’re just paying for what you’re using,” Ghodsi said. “In fact, there is no cluster to set up for it to be idle or not idle. So we’ll take care of all of that for you under the hood.”
Databricks runs on all the major clouds–AWS, Azure, and Google Cloud–and relies on those cloud platforms for storage, compute, and networking. Storage is pretty straightforward in the cloud, as Databricks expects customer data to be stored in their cloud object storage accounts, whether its S3 (Simple Storage Service) on AWS, ALCS (Azure Lake Cloud Storage) on Azure, or GCS (Google Cloud Storage) on GCP.

Databricks CEO Ali Ghodsi delivers a keynote at Data + AI Summit 2024 (Image courtesy Databricks)
But setting up the compute is more complicated. Customers may provision the compute for their ETL, streaming data, SQL analytics, or ML/AI training jobs through Databricks, but they’re billed for the compute through their account with the cloud platform. Going serverless changes that compute equation.
“All these knobs that we had before are gone,” Ghodsi said. “Cluster tuning–you have people setting up clusters. What type of machines should they use? Spot instances?…Should we auto scale? None of that is available anymore. It’s just gone. There’s no such page. You can’t do that.”
Going serverless also helps customers by reducing the need to understand past usage and use that for capacity planning purposes, Ghodsi said. (However, there’s a caveat around networking, as Databricks currently doesn’t charge for incurred network costs for serverless workloads, but reserves the right to do so in the future, according to its serverless documentation.)
There are also benefits to going serverless from the perspective of security and data layouts, Ghodsi said.
“We’re also able to do security a different way because again, we own all the machines and are able to really lock it down in a different way. That’s not possible when it’s not serverless,” he said. “The data layout–how are you going to set out exactly your data sets? How are you going to optimize your data sets? That’s also gone. We’re just optimizing behind the scenes. Because it’s serverless, we just run in the background optimization on your data set to make it really fast and optimal using machine learning. So that’s also really awesome.”
Databricks will benefit from the shift away from versioning software releases; there will be no more versions, as Databricks will automatically update the software, giving all users access to the same fixes and features at the same time.
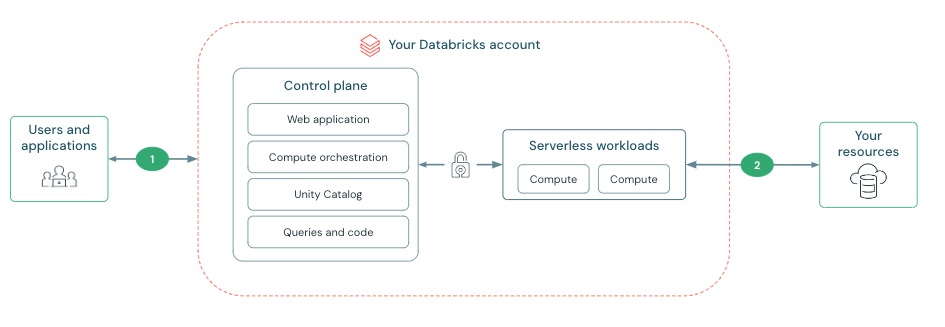
The Databricks Compute Plane (Image courtesy Databricks)
Databricks engineers spent the past three years working on the serverless version of its platform, Ghodsi said. It took that long because the engineers essentially had to rewrite all of its offerings, which is something that was a matter of debate within the company.
“Two to three years ago, my cofounder Matei [Zaharia, Databricks’ CTO] and I told the company ‘We’ve got to build a lift-and-shift, simple version of serverless.’ And actually our engineers pushed back, and said ‘Hey, you guys are wrong. We should redesign it from scratch for the serverless era.’ And we told them ‘Nope. We decide in the company.’ And it turned out we were wrong. The tech leads were right. And they’ve been working really hard for two years to basically redesign many of the products–the notebooks, the jobs, everything–as if we have started a new company.”
The shift to serverless won’t happen overnight on June 30 (even though it is a Sunday, which is ideal). It will take time to transition all 12,000 Databricks customers to the serverless versions of the products they’re using, whether it’s Spark clusters or Structured Streaming or notebooks or MosaicAI.
Databricks is making investments around the world to ensure serverless versions of its products are available in every cloud data center it runs. The company will be strongly encouraging customers to make the move to serverless sooner than later.
“Please start using serverless,” Ghodsi said. “In the future, new products that we roll out…they’ll probably only be available in serverless. So if your organization is not on serverless, please get on it.”
For more info on Databricks’ serverless, see the release notes.
Related Items:
Databricks to Open Source Unity Catalog
Databricks Unveils LakeFlow: A Unified and Intelligent Tool for Data Engineering
Leading Solution Providers

















