


October 9, 2024
Polars Gets GPU Support as Cloud Version Nears Launch
A new speedy DataFrame library called Polars is starting to turn heads in the data science community thanks to its performance and adoption rate. The open source project, which provides a multithreaded, vectorized query engine for analyzing and manipulating data in Python, recently gained support for GPUs. And with a cloud version launching soon by the commercial outfit behind Polars, the adoption curve seems likely to continue bending upward.
Polars started out as a side project for Ritchie Vink, a Dutch civil engineer-turned self-trained data scientist. Vink originally began Polars as a way to explore the use of query engines, Apache Arrow, and the Rust programming language. But when Vink made the code available as open source in June 2020, it quickly became apparent that Polars was much more.
Since then, Polars has gained more than 29,000 GitHub stars, making it one of the most popular DataFrame libraries around, narrowly trailing entrenched libraries like Apache Spark and Pandas, which have 39,500 and 43,500 stars, respectively. In July, as part of the Polars 1.0 launch, the Polars project announced that the software, which is available under an MIT license, was being downloaded 7 million times a month, and is being used by organizations like Netflix, Microsoft, and UCSF.
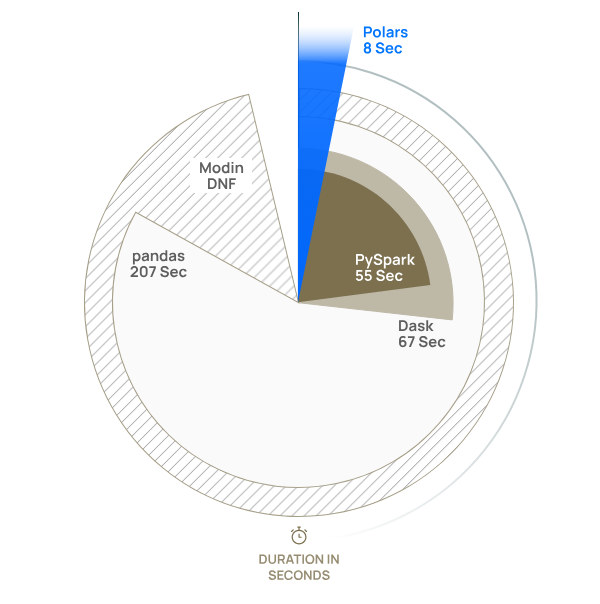
A TPC-H benchmark shows Polars beating other query engines (Image source Polars)
What has driven this intense interest in Polars and such rapid adoption? To quote Lightning McQueen: Speed.
Polars is just plain fast. In April, the commercial outfit behind Polars, which Vink and fellow Xomni employee Chiel Peters co-founded in August 2023, published the results of a TPC-H benchmark. In a test of seven of 22 TPC-H queries on a 10GB dataset, Polars outperformed all other libraries in data wrangling tasks, including DuckDB, PySpark, Dask, Pandas, and Modin (although DuckDB outperformed Polars in some categories). Compared to pandas, Polars completed the data wrangling task 25 times quicker.
“Polars easily trumps other solutions due to its parallel execution engine, efficient algorithms and use of vectorization with SIMD (Single Instruction, Multiple Data),” the company says.
Polars was designed to run on a variety of systems, from laptops to on-prem clusters to resources running in the cloud. The library was written natively in Rust, which the company says gives it exceptional performance and fine-grained memory handling. It also Apache Arrow, which provides integration with other tools at the memory layer and eliminates the need to copy data.
“Polars was written from scratch in Rust, and therefore didn’t inherit bad design choices from its predecessors, but instead learned from them,” Vink wrote in 2023. “Cherry picking good ideas, and learning from mistakes.”
Vink says the main drivers of Polars’ speed boil down to a handful of design principles. For starters, it offers a “strict, consistent, and composable API. Polars gives you the hangover up front and fails fast, making it very suitable for writing correct data pipelines,” he says.

Ritchie Vink, the creator of Polars and the CEO and Co-founder of a company by the same name
Pandas also brings a query planner, which helps its job as a front-end to an OLAP engine. “I believe a DataFrame should be seen as a materialized view. What is most important is the query plan beneath it and the way we optimize and execute that plan,” Vink writes.
Customers shouldn’t have to put up with the lower performance bounds of pandas, which is single-threaded. Pandas also uses NumPy, “even though it is a poor fit for relational data processing… Any other tool that utilizes pandas inherits the same poor data types and the same single threaded execution. If the problem is GIL [global interpreter lock] bound, we remain in single threaded Python land.”
In late September, Polars (the company) announced the open beta of a Polars GPU engine. By integrating Nvidia’s RAPIDS cuDF into the project, Polars customers can take advantage of the extreme parallelism of GPUs, providing up to a 13x performance boost compared to running Polars on CPUs.
The combination of Polars running on GPUs via RAPIDS cuDF enables users to process hundreds of millions of rows of data on a single machine in less than two seconds, according to a blog post by Nvidia product marketing manager Jamil Semaan.
“Traditional data processing libraries like pandas are single-threaded and become impractical to use beyond a few million rows of data. Distributed data processing systems can handle billions of rows but add complexity and overhead for processing small-to-medium size datasets,” Semaan writes.
“Polars…was designed from the ground up to address these challenges,” he continues. “It uses advanced query optimizations to reduce unnecessary data movement and processing, allowing data scientists to smoothly handle workloads of hundreds of millions of rows in scale on a single machine. Polars bridges the gap where single-threaded solutions are too slow, and distributed systems add unnecessary complexity, offering an appealing ‘medium-scale’ data processing solution.”
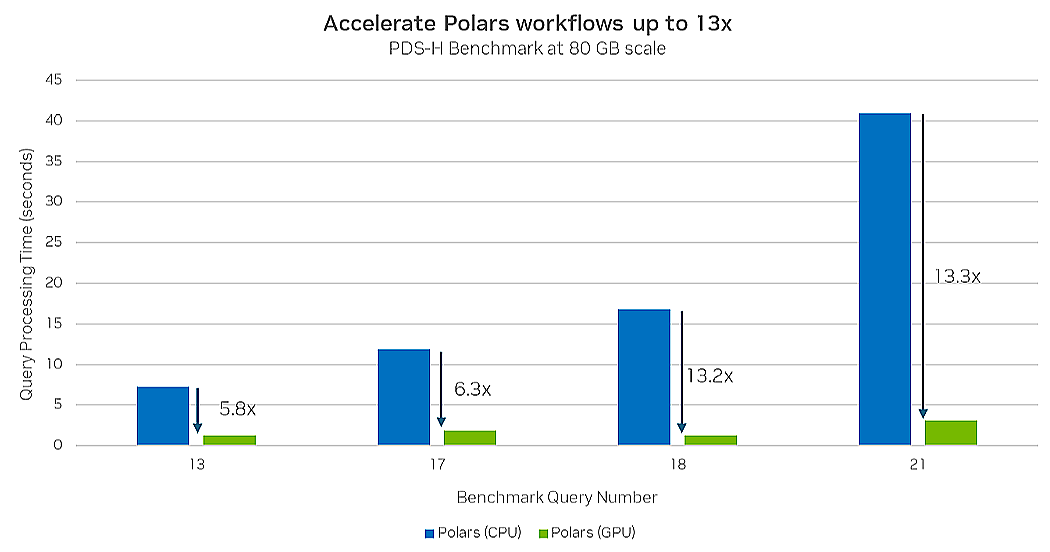 Running Polars on GPUs gives it a 13x boost over CPUs (Image source Nvidia)
Running Polars on GPUs gives it a 13x boost over CPUs (Image source Nvidia)As adoption of open source Polars spreads, Vink and Peters are taking the DataFrame library into the cloud. Later this year, the Polars company is expected to launch Polars Cloud, which will allow customers to get Polars systems up and running quickly on systems managed by AWS. The company is encouraging customers to sign up for the wait list here.
In the meantime, early adopters seem happy to be getting the performance benefits of Polars that are available now.
“The speedup of Polars compared to pandas is massively noticeable,” Casey H, a machine learning engineer at G-Research, says on the Polars website. “I generally enjoy writing code that I know is fast.”
“Polars revolutionizes data analysis, completely replacing pandas in my setup,” Matt Whitehead, a quantitative researchers at Optiver, says in a blurb on the Polars website. “It offers massive performance boosts, effortlessly handling data frames with millions of rows….Polars isn’t just fast – it’s lightning-fast.”
“Migrating from pandas to Polars was surprisingly easy,” Paul Duvenage, a senior data engineer at Check, writes in a blurb that appears on the Polars website. “For us, the results speed for themselves. Polars not only solved our initial problem but opened the door to new possibilities. We are excited to use Polars on future data engineering projects.”
Related Items:
From Monolith to Microservices: The Future of Apache Spark
Data Engineering in 2024: Predictions For Data Lakes and The Serving Layer
Apache Arrow Announces DataFusion Comet
Applications:
Data Management
Sectors:
Biosciences
Leading Solution Providers

















