


December 4, 2024
A Tale of Two Cities: Data Fabric and Data Mesh

(metamorworks/Shutterstock)
In today’s data-driven world, organizations are increasingly focused on transforming their data into valuable products that can be easily accessed and consumed across the enterprise. By offering data products through internal data marketplaces, businesses aim to empower data consumers with the insights and tools needed to drive data decision-making. According to new research, 76% of businesses say data-driven decision-making is a top goal for 2025, yet 67% don’t completely trust the data used by their organization for decision-making purposes.
Data products empower business users to make better business decisions, drive innovation, and improve customer experiences by providing easy access to relevant and high integrity data. For example, a marketing team can use a data product to analyze customer behavior and create targeted campaigns. Ultimately the goal is to provide faster access to data at scale by providing pre-built data products via marketplaces to data consumers.
Data products, such as dashboards, reports, APIs, data visualizations, and machine learning models, have measurable value and are reusable. They are designed to deliver trusted data to solve business problems. This demand for scalable, flexible access to data has given rise to architectural approaches like data fabric and data mesh, each designed to address the complexities of modern data environments and help organizations unlock the full potential of their data assets.
What is Data Mesh?
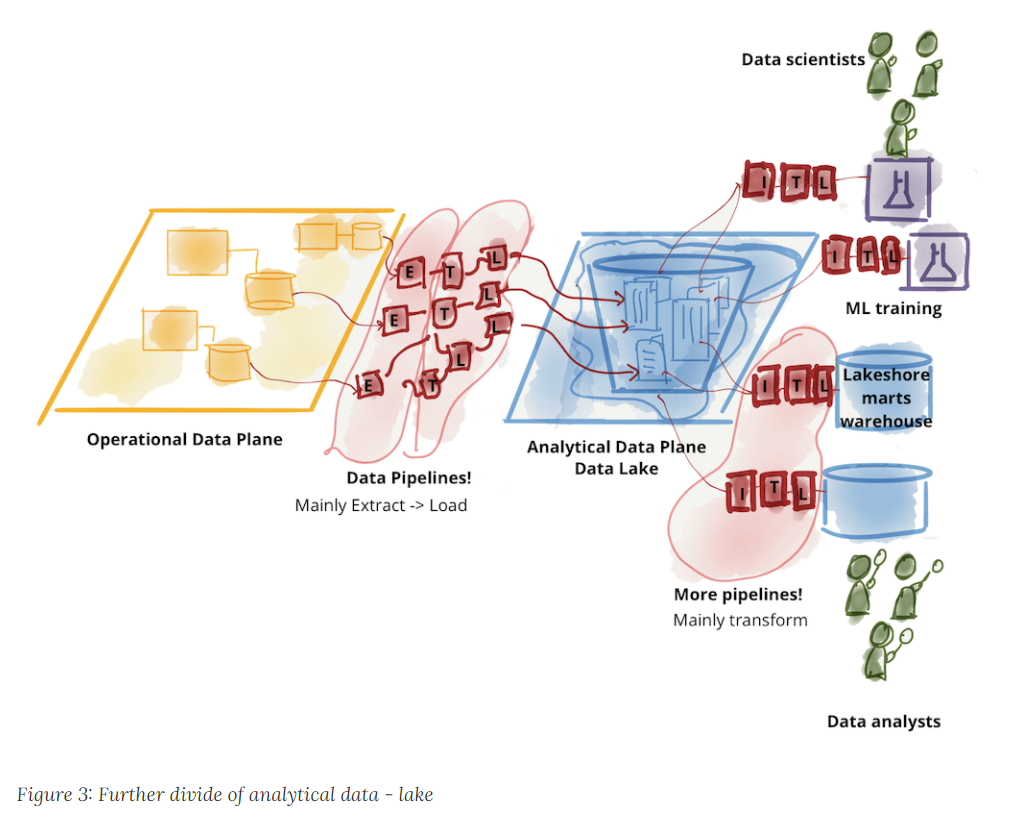
Data mesh is a decentralized approach to data architecture. Rather than a centralized data team owning all data assets, each business unit or domain team within an organization takes ownership of their data, treating it as a product. The goal is to create a self-service, scalable architecture that enables teams to operate autonomously and reduce dependency on IT, while adhering to shared governance and interoperability standards. Data mesh works well for organizations that have a data-driven culture and clear ownership of data, where teams already operate independently and can own data product responsibilities.
However, success with data mesh requires robust governance to ensure data consistency,
Data mesh (Source: Zhamak Dehghani)
accessibility, and security. This includes using observability tools to monitor data pipelines and maintaining a comprehensive data catalog to ensure data products are discoverable and usable. Additionally, organizations should consider a channel or infrastructure that enables users to access data products easily, such as a data marketplace.
What is Data Fabric?
Data fabric is an end-to-end, unified architecture that brings together the primary data and analytics tools that organizations need. Leveraging AI and machine learning, these technologies are enhanced with advanced capabilities to automate and optimize data management processes, creating a unified, consistent, and integrated data environment across your systems and platforms. This unified architecture effectively eliminates silos and fosters agility by dynamically generating data products through automated metadata management and AI-powered insights. Through a combination of data integration techniques, active metadata management practices, and other specialized data management tools including knowledge graph, recommendations and data products emerge dynamically from the fabric through automation, activation, and AI/ML analysis of metadata.
This centralization is particularly beneficial for organizations transitioning from legacy systems to modern, cloud-native environments.
Approaching Data Management with the Right Architecture
Data mesh and data fabric are modern data architecture paradigms that aim to address the challenges of managing data in complex, distributed environments. While they share some similarities, they also have distinct characteristics that make them suitable for different use cases and can even be used in combination.

Data fabric (Image source: Gartner)
An organization’s data maturity heavily influences which framework might be the better fit. For organizations with a relatively high level of data maturity and a data-driven culture, data mesh may be a viable option. These organizations typically have a well-established data governance model, mature data pipelines, and teams that are ready to take responsibility for their own data assets.
For organizations where data governance is still evolving, particularly where they may not be strong coordination between different teams, data fabric might be the best choice. It allows for centralized governance while enabling organizations to gradually scale their data architecture across distributed environments. Data fabric is also better suited for organizations with higher metadata maturity, as it focuses on driving intelligence from metadata.
Data Maturity and Active Metadata: Foundations for Informed Decision-Making
Regardless of the framework chosen, metadata management is a critical element for both data mesh and data fabric. Metadata, such as technical, operational, or business metadata, is essential for enabling effective data discovery, governance, and impact analysis.
Active metadata refers to metadata that is automatically collected, updated, and utilized in real time to enhance data management processes. It goes beyond static descriptions of data by continuously monitoring and enriching metadata with insights, such as usage patterns, data lineage, and data quality metrics. Data observability plays an important role for active metadata for setting alerts and monitoring patterns and detecting any deviations from historical trends.
In the context of data fabric, active metadata is crucial because it powers automation and AI-driven processes, enabling organizations to dynamically optimize data integration, quality monitoring, governance, and security. This real-time intelligence allows for faster, more accurate decision-making and greater operational efficiency across distributed data environments.
Choosing between data mesh and fabric depends on your organization’s data maturity and operational model. A hybrid approach may be more powerful – bringing the data close to subject matter experts and data domains while sharing best practices for security and governance via central teams.
Both frameworks have their merits, but neither can succeed without a strong data integrity foundation and a clear strategy for managing metadata. Before adopting either, organizations must ensure they have the necessary infrastructure, data culture, and governance in place to maximize the value of their data. Ultimately, the goal is to provide trusted, scalable data products that deliver business value and having accurate, consistent, and contextualized data is crucial for achieving trust.
About the author: Tendü Yogurtçu is the CTO of Precisely, where she directs the company’s technology strategy, product innovation, and research and development programs. Yogurtçu has more than 25 years of software industry experience and a PhD in computer science from Stevens Institute of Technology, where she was an adjunct faculty member. Yogurtçu was named CTO of the Year for the Women in IT Awards in 2019 and in 2018 was recognized as an Outstanding Executive in Technology by Advancing Women in Technology (AWT). Yoğurtçu is a member of the Forbes Technology Council, an Advisory Board Member at Stevens Institute of Technology School of Engineering and Science, and Executive Advisory Board Member for DNX Ventures.
product innovation, and research and development programs. Yogurtçu has more than 25 years of software industry experience and a PhD in computer science from Stevens Institute of Technology, where she was an adjunct faculty member. Yogurtçu was named CTO of the Year for the Women in IT Awards in 2019 and in 2018 was recognized as an Outstanding Executive in Technology by Advancing Women in Technology (AWT). Yoğurtçu is a member of the Forbes Technology Council, an Advisory Board Member at Stevens Institute of Technology School of Engineering and Science, and Executive Advisory Board Member for DNX Ventures.
Related Items:
Data Governance Programs Expand, But Trust in Data Declines, Precisely Finds
Data Mesh Vs. Data Fabric: Understanding the Differences
The Data Mesh Emerges In Pursuit of Data Harmony
Leading Solution Providers

















