


February 10, 2025
Memgraph Bolsters AI Development with GraphRAG Support

The best GenAI applications combine the freshest, most pertinent customer data with top language models, but getting that data into the model’s context window isn’t easy. That’s where the new GraphRAG capability announced today by in-memory graph database Memgraph comes into play.
Memgraph develops an in-memory graph database that excels at real-time use cases that are a mix of transactional and analytical workloads, such as fraud detection and supply chain planning. It was launched as an open source offering in 2016 by Dominik Tomicevic and Marcko Budiselić, who found that traditional graph databases couldn’t handle the demands of this particular type of application.
Traditional graph databases, such as Neo4j, are batch oriented and store data on disk. This works well when you want to ask a wide range of graph questions on large amounts of slow-moving data, but it doesn’t work well when you need quick answers on faster moving but smaller data sets, Tomicevic says.
“The problem begins if you have lots of writes per second (hundreds of thousands or millions per second),” the Memgraph CEO tells BigDATAwire. “Neo4j can’t handle that kind of writes per second, especially being responsive at the same time to the read queries and analytics.”
Neo4j offers high-performance graph algorithms and analytics via its Graph Data Science (GDS) library. However, GDS requires works essentially as a separate database, which doesn’t address real-time needs.
Instead of trying to fit analytic use cases into a batch graph database, Tomicevic and Budiselić decided to build a graph database from scratch that caters to this particular type of workload. Memgraph stores all data in RAM, providing not only fast data ingest but also the capability to run analytics and data science algorithms on the entirety of the graph.

Memgraph CTO Marcko Budiselić (left) and CEO Dominik Tomicevic
This approach brings tradeoffs, of course. Storing data in RAM is orders of magnitude more expensive than storing it on disk. Customers will not be able to build massive graphs on Memgraph, which is built on a scale-up architecture (a distributed architecture would introduce too much latency). The typical Memgraph databases have a few hundreds of millions of nodes and edges, while some of the largest have single-digit billions of edges. Graphs in Neo4j can be much bigger, measured in the trillions of nodes, with a theoretical limit in the quadrillions.
But for certain types of high-value workloads, Memgraph provides the right mix of real-time ingest and analytics capabilities that providing customer value. It uses Neo’s open source Cypher query graph language, which means Memgraph is a drop-in replacement, Tomicevic points out.
GraphRAG in Memgraph 3.0
With today’s launch of Memgraph 3.0, the company is taking its real-time analytics investment into the world of generative AI. It is launching a pair of new features with Memgraph 3.0 that position the database to be more useful for emerging GenAI workloads, such as serving chatbots or AI agents.
The first new feature in Memgraph 3.0 is the addition of vector search. By storing graph data as vector embeddings, users will be able to serve explicit relationships (as defined by the graph nodes and edges) into the context windows of language models to get a better result as part of a RAG pipeline, or GraphRAG.
Language model context windows are getting very large. For instance, Google’s Gemini 2.0 model, which was made available to everyone last week, can now accept 2 million tokens in its context window. That is a lot of data, equivalent to about 1.5 million words, but that, in and of itself, may not be enough to ensure accuracy.
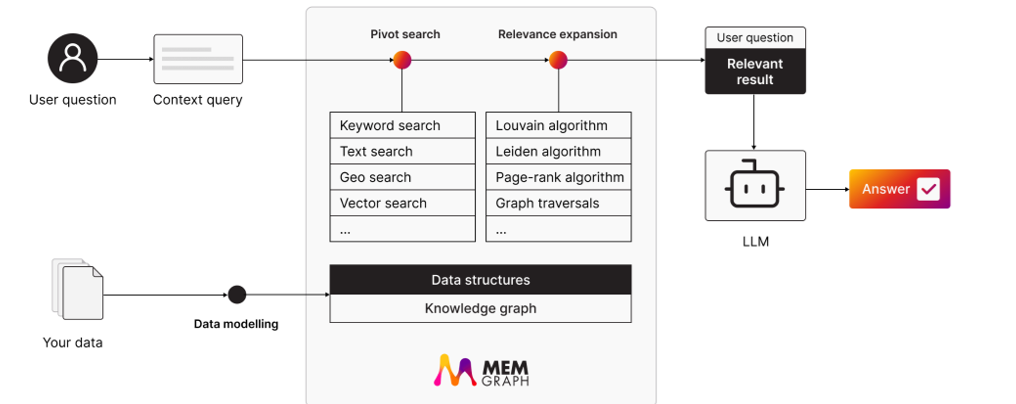
Memgraph 3.0 supports GraphRAG (Image courtesy Memgraph)
“Even if you had that, that would probably be a problem for just picking out what the right information is,” Tomicevic says. “We can leverage some of the traditional graph algorithms with community detection to group the data into groups that make sense, and then you can do partial summarization on each group.”
Memgraph is providing basic vector capabilities with version 3.0. If customers need more advanced features, they can integrate Memgraph with dedicated vector databases, such as Pinecone, Tomicevic says.
GraphRAG support in Memgraph will also cut down on the tendency for language models to hallucinate and provide higher quality answers overall, he says.
“There’s a lot of problems with just deploying LLMs and training and pre-training and fine tuning and other things,” the CEO says. “LLMs are terrible at accounting, for example. They’re also terrible at hierarchical relationships and thinking. If you have a graph and you understand that there’s a problem that is hierarchical, you can ask them to use the graph to break down the hierarchy, and then you can create a better overall answer than just traditional LLM would give you.”
For more information on Memgraph’s support for GraphRAG, see memgraph.com/docs/ai-ecosystem/graph-rag.![]()
Natural Language Graphs
Memgraph 3.0 also brings enhancements to GraphChat, a natural language interface for Cypher. With this release, Memgraph customers can ask a graph question in plain English, and GraphChat will convert it to Cypher for execution on Memgraph. This will have the impact of lowering the barrier to accessing sophisticated graph data science capabilities, Tomicevic says.
“Graphs are very powerful. They can do a lot of things,” he says. “[With GraphChat] they become more in reach of the people who don’t have a graph PhD, if you will. It can be the developers that are developing these applications and they can make them more productive.”
Memgraph is also supporting models from DeepSeek, the Chinese developer that burst onto the AI scene just a few weeks ago with a reasoning model comparable to those from OpenAI. The company has also introduced performance and reliabity improvements with version 3.0, as well as updates to Python libraries and the Docker package.
Related Items:
The Future of GenAI: How GraphRAG Enhances LLM Accuracy and Powers Better Decision-Making
O’Reilly and Cloudera Announce Inaugural Strata Data Awards Finalists
Graph Databases Everywhere by 2020, Says Neo4j Chief
Leading Solution Providers

















