


February 26, 2014
NoSQL Databases RAM it Home with In-Memory Speedups
In-memory processing has long been used in analytic NoSQL database. But now transaction oriented NoSQL databases, like those from DataStax and MongoDB, are getting the in-memory treatment, which is leading to speedups in the range of 10x to 100x–sometimes much more.
![]() DataStax today announced that it has added an in-memory computing option to DataStax Enterprise (DSE) version 4.0, the latest release of the commercialized version of the open source Cassandra database. The in-memory option allows DSE users to ensure that database tables with the hottest (or fastest changing) data are permanently pinned to RAM, thereby significantly speeding up transactions that deal with that data.
DataStax today announced that it has added an in-memory computing option to DataStax Enterprise (DSE) version 4.0, the latest release of the commercialized version of the open source Cassandra database. The in-memory option allows DSE users to ensure that database tables with the hottest (or fastest changing) data are permanently pinned to RAM, thereby significantly speeding up transactions that deal with that data.
The NoSQL database vendor developed the in-memory option at the request of customers who were using third-party in-memory caching technologies to speed up certain parts of their DSE apps, says DataStax vice president of products Robin Schumacher. “They would put something alongside us, like either a Memcached or a Redis, to solve those challenges,” Schumacher tells Datanami. “They said, ‘We’d really like to have this under one umbrella so why don’t you do that?'” So they did.
Benchmark shows the in-memory option can be counted on to deliver a 10x to 100x uptick in performance on common apps compared to disk. (A 1,000x speedup was spotted in one circumstance where the app had completely exhausted the Linux OS page cache, but that will be a rarity in the wild.) The company doesn’t see customers putting their entire databases into memory. That just wouldn’t be feasible when DSE is storing several hundred terabytes across a geographically distributed cluster with dozens of nodes (more on that later).
Instead, Schumacher envisions customers running certain pieces of their applications in memory–such as “top movies” lists for Netflix (an actual DataStax customer) or the leaderboard for an online gaming company. These components are typically characterized by very fast-changing data, but the data size is relatively static.
 |
|
| In-memory tables demonstrate much lower intraprocess latency in a multi-node DSE cluster | |
The in-memory option doesn’t change how DSE operates, Schumacher says. “The new in-memory options brings all of Cassandra’s goodness–the multi data-center support, the flexible data model, linear scale–all that stuff, and it brings it to an in-memory database,” he says. “So now when you create a Cassandra table, you can specify it as an in-memory table. Once you hit enter, it looks, feels, tastes, acts just like any other Cassandra table will. It’s really easy to use and it’s transparent to an application. There’s nothing special you have to do from a development perspective.” At any time, users can move an in-memory table to a disk-oriented table, and vice versa, with a simple command.
However, in-memory computing does introduce new technical concerns that DSE users should keep in mind. If the data set in memory grows to exceed the amount of memory that’s available to the database, then bad things will happen. To help customers alleviate this concern, DataStax is shipping a new release of its OpsCenter add-on that brings new tooling aimed at alerting administrators to dangerous growth of in-memory tables. There are also new capacity planning tools that help admins forecast growth of in-memory tables.
The in-memory option is not a panacea for performance woes, Schumacher says. “People think that in-memory computing is a cure all for performance problems, and it’s really not,” he says. “You really need to be smart about how you utilize this. This is another knob, another option, that you have to really dial the performance that you need for your particular sets of data.”
Back to the In-Memory Future
DataStax competitor MongoDB is also up for the in-memory treatment, courtesy of GridGain Systems, a third-party developer of in-memory data grids. “We have a product coming up for MongoDB,” GridGain founder Nikita Ivanov said at the Hadoop Innovation Summit held last week in San Diego. “You can drop in a GridGain in a Mongo installation and get an instant performance increase.”
![]() GridGain is one of the companies at the forefront of adapting in-memory data grids to big data problems. The company has already integrated its technology with Hadoop and relational databases, and is also working with customers in the area of HPC and complex event processing.
GridGain is one of the companies at the forefront of adapting in-memory data grids to big data problems. The company has already integrated its technology with Hadoop and relational databases, and is also working with customers in the area of HPC and complex event processing.
As the cost of RAM continues to decline, the IT industry will naturally move to in-memory computing, Ivanov says. “Storing data in memory is really the last frontier,” he says. “Where else can we move without fundamentally changing the architecture of computers? There’s practically nowhere. About the only thing you could change would be to move in on the CPU itself, where the CPU caches the data, but that’s going to be tough.”
For $25,000 today, customers can buy a 1TB cluster of commodity hardware to run their in-memory data grid on, Ivanov says. By 2015, that cost will have dropped to about $10,000. That is one of the reasons why Gartner predicts in-memory data grids to be a $1 billion business in several years. “Those who aren’t considering in-memory compute today risk being out-innovated by competitors that are early adopters,” Ivanov says.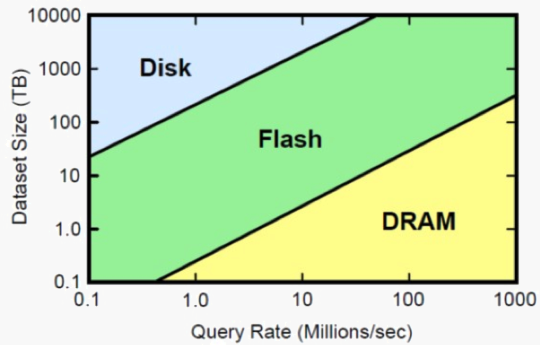
How big is big enough? According to Ivanov, the biggest in-memory data grids run by one of its customers is about 10TB across 150 nodes, with the mean being in the 1TB-to-3TB range. But these grids are puny compared to the grids in development today, according to Ivanov.
“Companies in Silicon Valley…have active projects that have multiple hundreds of terabytes of RAM, available literally within months, or maybe a year from now. Easily we’re talking about hundreds of terabytes of RAM availed in commodity hardware,” he says. “It’s just a matter of productizing it, getting the price point, and shipping it.”
Related Items:
Look Out, Mongo, Here Comes Couchbase
Taking NoSQL to the Next Level with In-Memory Computing
Applications:
Complex Event Processing
Technologies:
Cloud
Leading Solution Providers

















