


March 4, 2024
Anthropic Introduces Claude 3 Model Family: Haiku, Sonnet, and Opus
March 4, 2024 — Anthropic today announced the Claude 3 model family, which sets new industry benchmarks across a wide range of cognitive tasks. The family includes three state-of-the-art models in ascending order of capability: Claude 3 Haiku, Claude 3 Sonnet, and Claude 3 Opus.
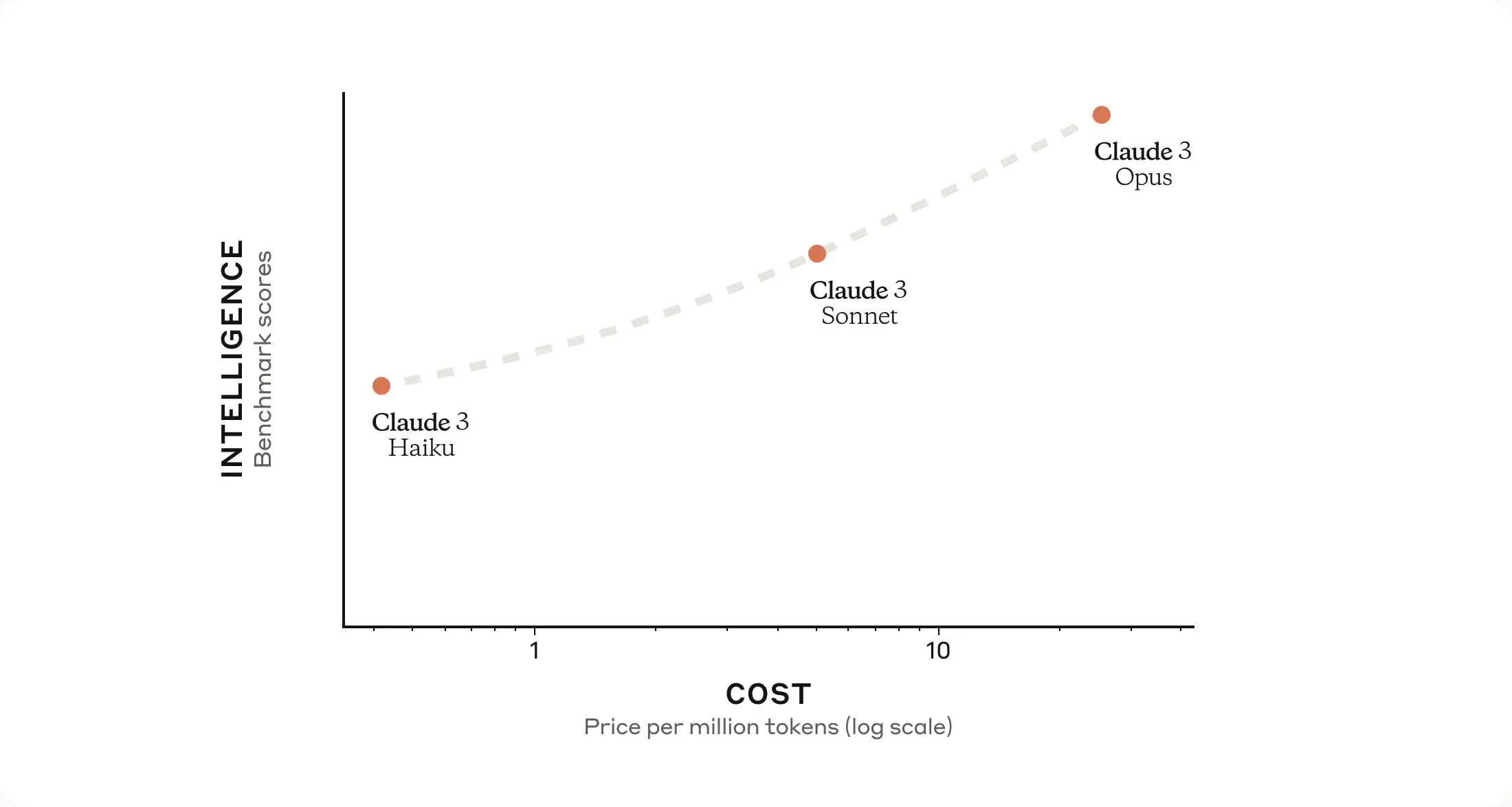
Each successive model offers increasingly powerful performance, allowing users to select the optimal balance of intelligence, speed, and cost for their specific application.
Opus and Sonnet are now available to use in claude.ai and the Claude API which is now generally available in 159 countries. Haiku will be available soon.
A New Standard for Intelligence
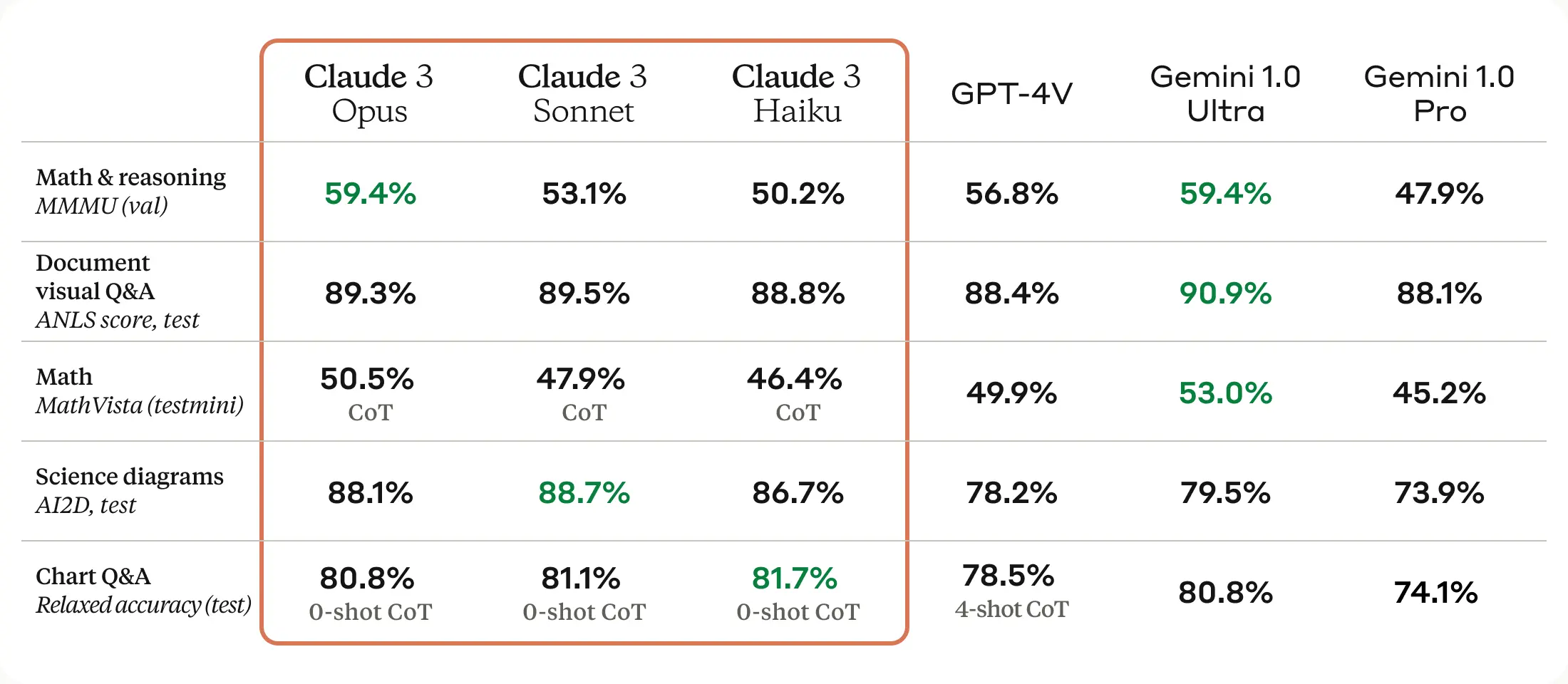
Opus, the Claude 3 model family’s most intelligent model, outperforms its peers on most of the common evaluation benchmarks for AI systems, including undergraduate level expert knowledge (MMLU), graduate level expert reasoning (GPQA), basic mathematics (GSM8K), and more. It exhibits near-human levels of comprehension and fluency on complex tasks, leading the frontier of general intelligence.
All Claude 3 models show increased capabilities in analysis and forecasting, nuanced content creation, code generation, and conversing in non-English languages like Spanish, Japanese, and French.
Below is a comparison of the Claude 3 models to those of Anthropic’s peers on multiple benchmarks of capability:

Near-Instant Results
The Claude 3 models can power live customer chats, auto-completions, and data extraction tasks where responses must be immediate and in real-time.
Haiku is the fastest and most cost-effective model on the market for its intelligence category. It can read an information and data dense research paper on arXiv (~10k tokens) with charts and graphs in less than three seconds. Following launch, Anthropic expects to improve its performance even further.
For the vast majority of workloads, Sonnet is 2x faster than Claude 2 and Claude 2.1 with higher levels of intelligence. It excels at tasks demanding rapid responses, like knowledge retrieval or sales automation. Opus delivers similar speeds to Claude 2 and 2.1, but with much higher levels of intelligence.
Strong Vision Capabilities
The Claude 3 models have sophisticated vision capabilities on par with other leading models. They can process a wide range of visual formats, including photos, charts, graphs and technical diagrams. Anthropic is particularly excited to provide this new modality to its enterprise customers, some of whom have up to 50% of their knowledge bases encoded in various formats such as PDFs, flowcharts, or presentation slides.
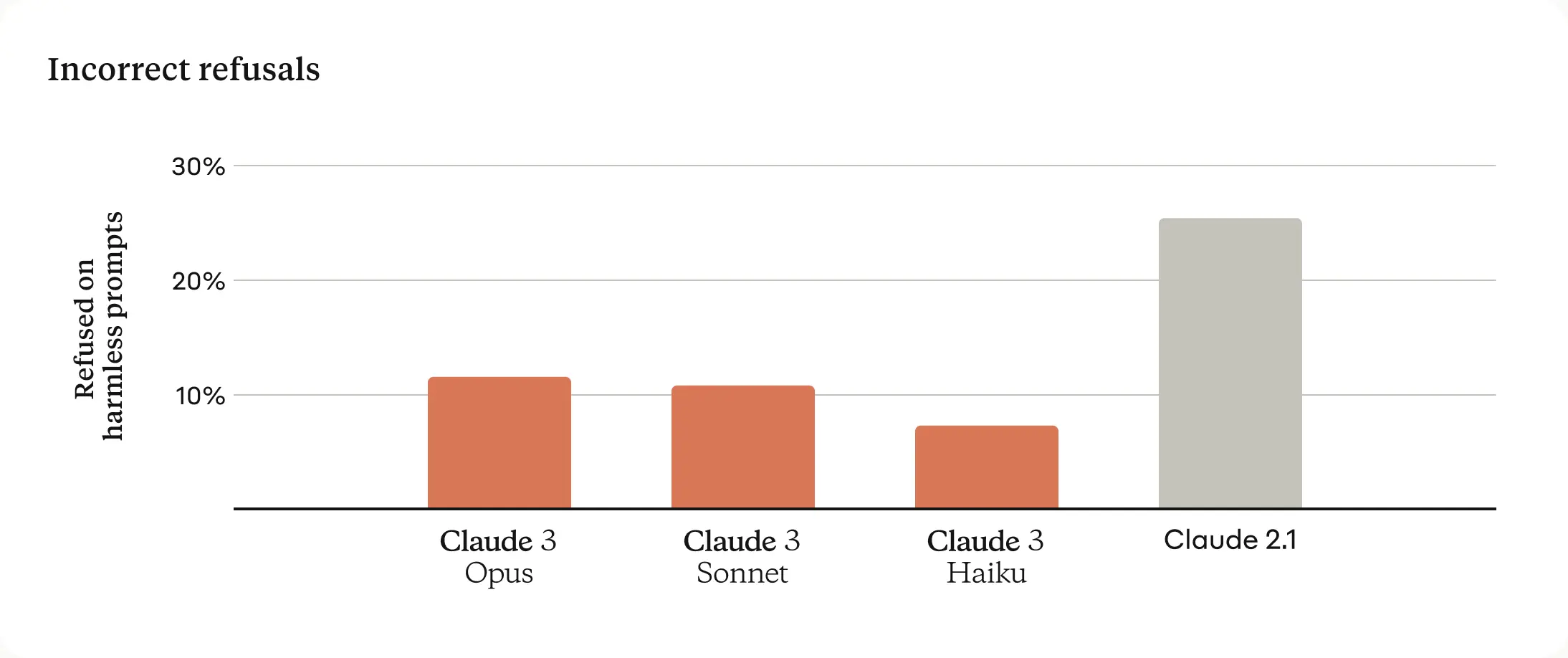
Fewer Refusals
Previous Claude models often made unnecessary refusals that suggested a lack of contextual understanding. Anthropic has made meaningful progress in this area: Opus, Sonnet, and Haiku are significantly less likely to refuse to answer prompts that border on the system’s guardrails than previous generations of models. As shown below, the Claude 3 models show a more nuanced understanding of requests, recognize real harm, and refuse to answer harmless prompts much less often.
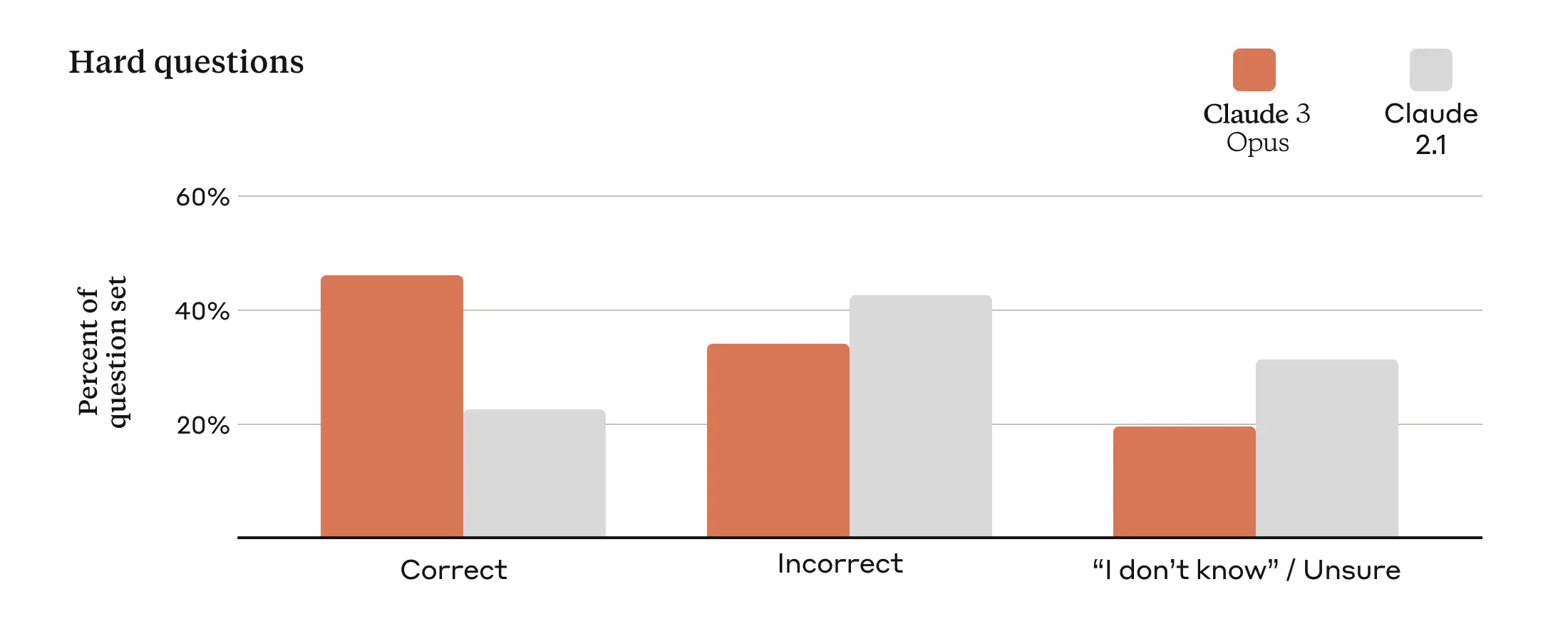
Improved Accuracy
Businesses of all sizes rely on Anthropic models to serve their customers, making it imperative for model outputs to maintain high accuracy at scale. To assess this, Anthropic uses a large set of complex, factual questions that target known weaknesses in current models. Anthropic categorizes the responses into correct answers, incorrect answers (or hallucinations), and admissions of uncertainty, where the model says it doesn’t know the answer instead of providing incorrect information.
Compared to Claude 2.1, Opus demonstrates a twofold improvement in accuracy (or correct answers) on these challenging open-ended questions while also exhibiting reduced levels of incorrect answers. In addition to producing more trustworthy responses, Anthropic will soon enable citations in our Claude 3 models so they can point to precise sentences in reference material to verify their answers.
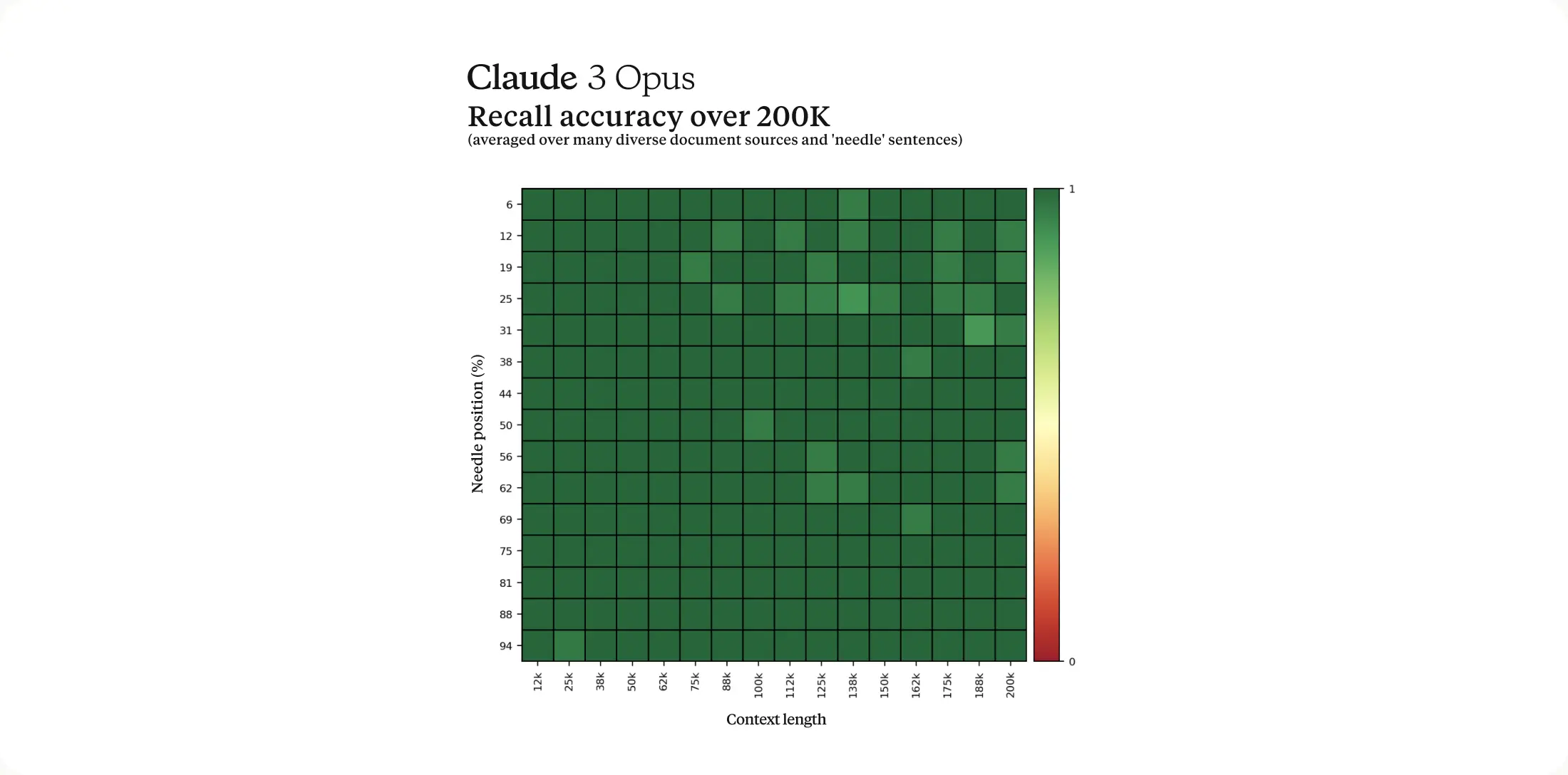
Long Context and Near-Perfect Recall
The Claude 3 family of models will initially offer a 200K context window upon launch. However, all three models are capable of accepting inputs exceeding 1 million tokens and Anthropic may make this available to select customers who need enhanced processing power.
To process long context prompts effectively, models require robust recall capabilities. The ‘Needle In A Haystack’ (NIAH) evaluation measures a model’s ability to accurately recall information from a vast corpus of data. Anthropic enhanced the robustness of this benchmark by using one of 30 random needle/question pairs per prompt and testing on a diverse crowdsourced corpus of documents. Claude 3 Opus not only achieved near-perfect recall, surpassing 99% accuracy, but in some cases, it even identified the limitations of the evaluation itself by recognizing that the “needle” sentence appeared to be artificially inserted into the original text by a human.
Responsible Design
Anthropic has developed the Claude 3 family of models to be as trustworthy as they are capable. The company has several dedicated teams that track and mitigate a broad spectrum of risks, ranging from misinformation and CSAM to biological misuse, election interference, and autonomous replication skills.
Anthropic continues to develop methods such as Constitutional AI that improve the safety and transparency of its models, and have tuned the models to mitigate against privacy issues that could be raised by new modalities.
Addressing biases in increasingly sophisticated models is an ongoing effort and Anthropic has made strides with this new release. As shown in the model card, Claude 3 shows less biases than previous models according to the Bias Benchmark for Question Answering (BBQ). Anthropic remains committed to advancing techniques that reduce biases and promote greater neutrality in our models, ensuring they are not skewed towards any particular partisan stance.
While the Claude 3 model family has advanced on key measures of biological knowledge, cyber-related knowledge, and autonomy compared to previous models, it remains at AI Safety Level 2 (ASL-2) per our Responsible Scaling Policy.
Anthropic’s red teaming evaluations (performed in line with our White House commitments and the 2023 US Executive Order) have concluded that the models present negligible potential for catastrophic risk at this time. Anthropic will continue to carefully monitor future models to assess their proximity to the ASL-3 threshold. Further safety details are available in the Claude 3 model card.
Source: Anthropic
Leading Solution Providers

















